



大数据分析命令行工具有哪些
2020-09-14
点击量:次
这大数据分析命令行工具有哪些是对十二种类Unix操作系统命令行工具的简短概述,这些工具可用于大数据分析任务。该名单不包括任何一般的文件管理命令(pwd,ls,mkdir,rm,...)或远程会话管理工具(rsh,ssh,...),而是由公用事业这将是有用的从大数据分析的角度看,一般是涉及不同了数据检查和处理的程度。它们也都包含在典型的类Unix操作系统中。当然,它是基本的,但是我鼓励你在适当的情况下寻找其他命令示例。工具名称链接到Wikipedia条目,而不是手册页,因为在我看来,前者通常对新手更友好。
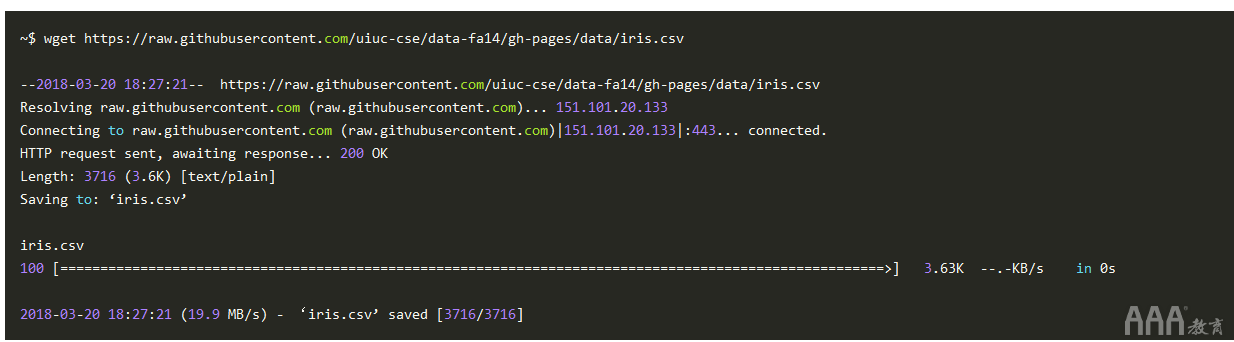
1、wget
wget是一种文件检索实用程序,用于从远程位置下载文件。以其最基本的形式,wget用于下载远程文件:
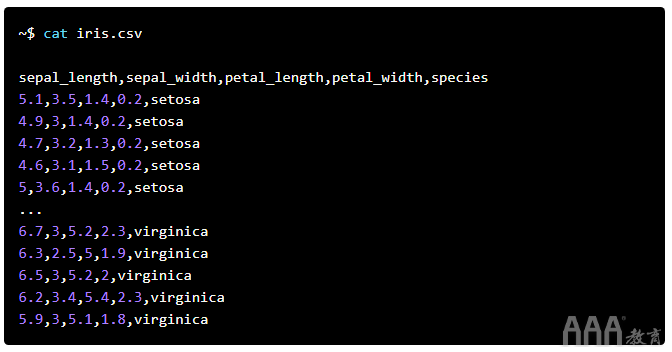
2、cat
cat是用于将文件内容输出到标准输出的工具。该名称来自串联。更复杂的用例包括将文件组合在一起(实际串联),将文件追加到另一个文件,对文件行编号等。
3、wc
该wc命令用于产生字数,行数,字节数以及与文本文件相关的内容。wc的默认输出在不带选项的情况下运行时,是一行,由左至右,行数,字数(请注意,每行不间断的单个字符串计为一个字),字符数和文件名。

4、head
head将文件的前n行(默认情况下为10)输出到标准输出。可以使用-n选项设置显示的行数。

5、tail
有什么猜测tail吗?


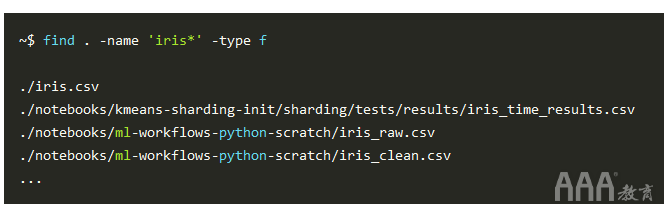
6、find
find是用于在文件系统中搜索特定文件的实用程序。以下内容从当前目录(“。”)开始的树结构中搜索以“ iris”开头并以常规文件类型(“ -type f”组成的任何哑字符(“ -name'iris *””)结尾的任何文件”):
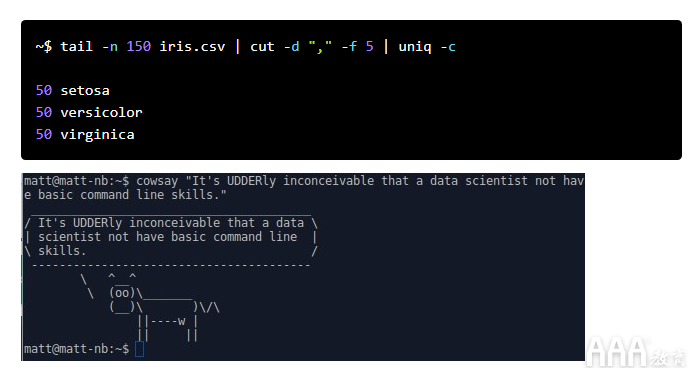
7、cut
cut用于从文件中切出一行文本。尽管可以使用多种标准来制作这些切片,但是cut可以用于从CSV文件中提取列数据。这将使用逗号作为字段分隔符(“ -d','”)输出iris.csv文件的第五列(“ -f 5”):

8、uniq
uniq通过将相同的连续行折叠为一个副本,将文本文件的输出修改为标准输出。单独看来,这似乎并不太有趣,但是当用于在命令行上构建管道时(将一个命令的输出插入另一个命令的输入,依此类推),这可能会变得有用。
以下内容为我们提供了第五列中保存的虹膜数据集类名称的唯一计数及其计数:
9、awk
awk实际上不是“命令”,而是一种完整的编程语言。它用于处理和提取文本,并且可以从命令行以单行命令形式调用。
精通awk需要花费一些时间,但是在此之前,这里是它可以完成的示例。考虑到我们的示例文件– iris.csv –相当有限(特别是在涉及文本多样性时),此行将调用awk,在给定文件(“ iris.csv”)中搜索字符串“ setosa”,并逐一打印到它遇到的项目(保存在$ 0变量中):
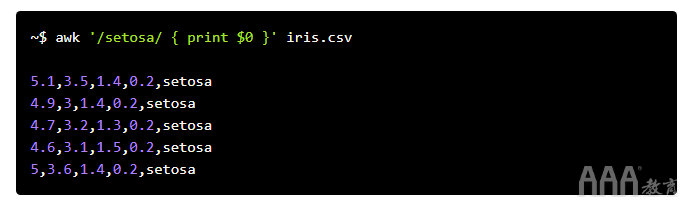
10、grep
grep 是另一种文本处理工具,用于字符串和正则表达式匹配。
如果你在命令行上花费大量时间进行文本处理,那么grep绝对是你会熟悉的工具。

11、sed
sed是一个流编辑器,是另一个文本处理和转换工具,类似于awk。我们在下面使用此行,使用此行将其在iris.csv文件中出现的“ setosa”更改为“ iris-setosa”:
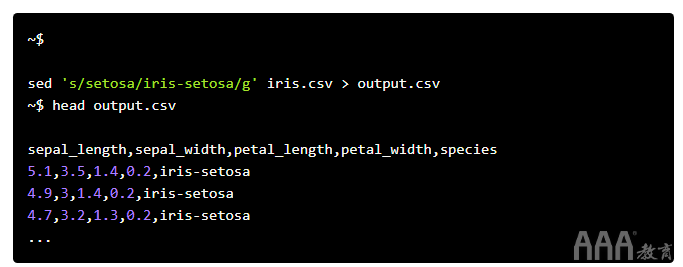
12、history
history 非常简单,但也很有用,尤其是当你要复制在命令行中完成的某些数据准备时。

在那里,你简单介绍了12种方便的命令行工具。这只是对命令行中大数据分析(或就此而言的其他任何目标)可能实现的一种尝试。让自己从鼠标中解放出来,观察生产率的提高。
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 大数据分析命令行工具有哪些
- 大数据分析