



大数据分析培训哪些内容
2021-05-12
点击量:次
大数据技术体系太庞杂了,基础技术覆盖数据采集、数据预处理、分布式存储、NOSQL数据库、多模式计算(批处理、在线处理、实时流处理、内存处理)、多模态计算(图像、文本、视频、音频)、数据仓库、数据挖掘、机器学习、人工智能、深度学习、并行计算、可视化等各种技术范畴和不同的层面。

另外大数据应用领域广泛,各领域采用技术的差异性还是比较大的。短时间很难掌握多个领域的大数据理论和技术,建议从应用切入、以点带面,先从一个实际的应用领域需求,搞定一个一个技术点,有一定功底之后,再举一反三横向扩展,这样学习效果就会好很多。接下来AAA教育小编来给大家分析下大数据培训的内容包括什么。
《大数据分析培训课程大纲》
一、Java语言基础
1、Java语言基础
Java开发介绍、熟悉Eclipse开发工具、Java语言基础、Java流程控制、Java字符串、Java数组与类和对象、数字处理类与核心技术、I/O与反射、多线程、Swing程序与集合类。
2、HTML、CSS与JavaScript
PC端网站布局、HTML5+CSS3基础、WebApp页面布局、原生JavaScript交互功能开发、Ajax异步交互、jQuery应用。
3、JavaWeb和数据库
数据库、JavaWeb开发核心、JavaWeb开发内幕。
二、 Linux&Hadoop生态体系
Linux体系、Hadoop离线计算大纲、分布式数据库Hbase、数据仓库Hive、数据迁移工具Sqoop、Flume分布式日志框架。
三、分布式计算框架
1、分布式计算框架
Python编程语言、Scala编程语言、Spark大数据处理、Spark—Streaming大数据处理、Spark—Mlib机器学习、Spark—GraphX 图计算、两个项目实战内容。
2、storm技术架构体系
Storm原理与基础、消息队列kafka、Redis工具、zookeeper详解、两个实战内容。
四、大数据项目实战
数据获取、数据处理、数据分析、数据展现、数据应用。
五、大数据分析
1、Data Analyze工作环境准备,数据分析基础、数据可视化、Python机器学习;
2、图像识别,神经网络、自然语言处理、社交网络处理、1个项目实战。
以上是大数据分析培训哪些内容的详细介绍,希望对大家有帮助。目前大数据正在快速发展中,对相关岗位人才的需求也在不断上升,入行大数据要抓住早期的时机。总之,想要在大数据分析行业里混的如鱼得水,就必须要掌握专业的大数据技术知识,大数据分析就业前景十分好,所以想要加入大数据分析行业中快速有效的方法就是选择到培训机构进行系统专业的学习。 AAA教育致力打造高端大数据分析人才,想学大数据分析的朋友要抓住这个机会,给自己的梦想插上翅膀。
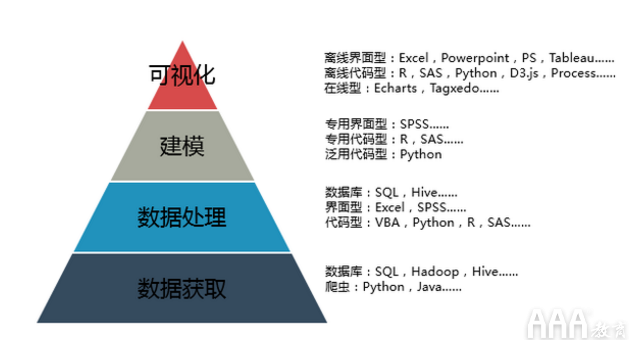
数据分析师的工具体系
Apache Hadoop: 是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
Apache Hive: 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Apache Pig: 是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
Apache HBase: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Apache Sqoop: 是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Apache Zookeeper: 是一个为分布式应用所设计的分布的、开源的协调服务,主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Apache Cassandra:是一套开源分布式NoSQL数据库系统。它由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身。
Apache Avro: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制。
Apache Ambari: 是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Apache Chukwa: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。
Apache Hama: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架,;Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
Apache Flume: 是一个分布的、可靠的、高可用的海量日志聚合的系统,可用于日志数据收集,日志数据处理,日志数据传输。
Apache Giraph: 是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
Apache Oozie: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Apache Crunch: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库。
Apache Whirr: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon EC2和Rackspace的服务。
Apache Bigtop: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。
Apache HCatalog: 是基于Hadoop的数据表和存储管理,实现中央的元数据和模式管理,跨越Hadoop和RDBMS,利用Pig和Hive提供关系视图。
Cloudera Hue: 是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 大数据分析培训哪些内容
- 大数据分析
- 大数据培训学校