



大数据中数据库是如何工作的(三)
2021-03-19
点击量:次
你知道如何建立数据库吗?动态编程,贪婪算法和启发式?大数据中数据库又是如何工作的?如果你对大数据专业有浓厚的兴趣,那么你可以接着看看以下内容。
优化器的真正工作是在有限的时间内找到一个好的解决方案。大多数情况下,优化器找不到最佳解决方案,而是找到“好的”解决方案。对于小的查询,可以使用蛮力方法。但是有一种方法可以避免不必要的计算,因此即使是中等查询也可以使用蛮力方法。这称为动态编程。
动态编程:这两个词背后的想法是,许多执行计划非常相似。
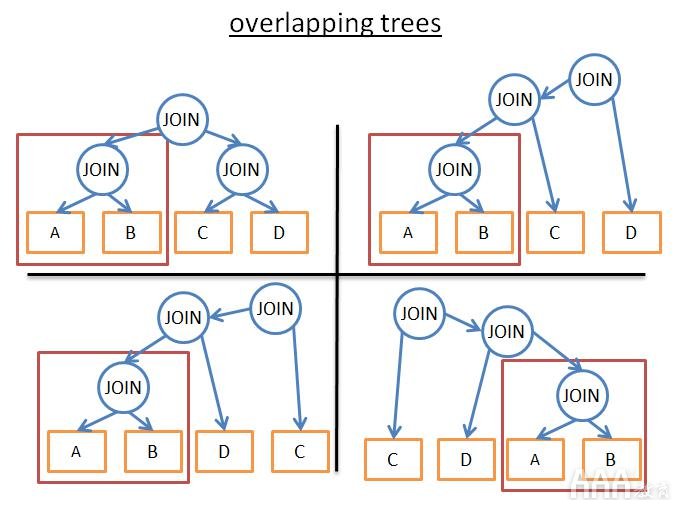
它们共享相同的(A JOIN B)子树。因此,与其在每个计划中都不计算此子树的成本,我们可以对其进行一次计算,保存计算的成本,并在再次看到此子树时重新使用它。为了避免对部分结果进行额外的计算,我们使用了记忆。
使用这种技术,而不是(2 * N)!/(N + 1)!时间复杂度,我们“只”有3 ñ。在我们前面的具有4个联接中,这意味着从336的顺序传递到81。如果你通过8个联接(不大)进行较大的查询,则意味着从57 657 600传递到6561。
在你已经了解动态编程或对算法精通的情况下才能更好的运用:
procedure findbestplan(S)
if (bestplan[S].cost infinite)
return bestplan[S]
// else bestplan[S] has not been computed earlier, compute it now
if (S contains only 1 relation)
set bestplan[S].plan and bestplan[S].cost based on the best way
of accessing S /* Using selections on S and indices on S */
else for each non-empty subset S1 of S such that S1 != S
P1= findbestplan(S1)
P2= findbestplan(S - S1)
A = best algorithm for joining results of P1 and P2
cost = P1.cost + P2.cost + cost of A
if cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]
对于更大的查询,你仍然可以采用动态编程方法,但是要使用额外的规则(或启发式方法)来消除可能性:
如果仅分析某种类型的计划(例如,左深树),则最终得到n * 2 n而不是3 n
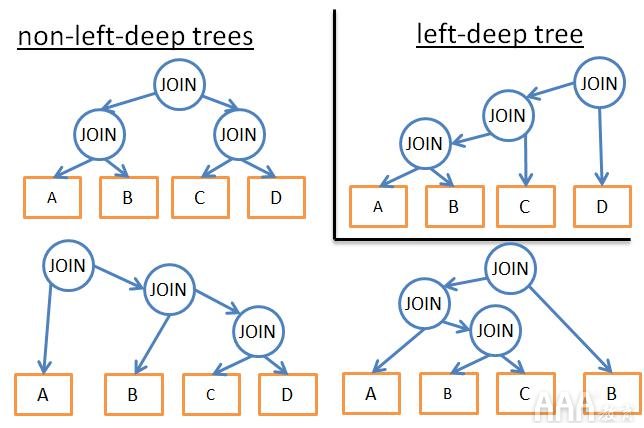
如果添加逻辑规则来避免针对某些模式的计划(例如“如果表作为给定谓词的索引,则不要尝试对表进行合并联接,而仅对索引进行尝试”),它将减少可能性的数量而不会损害尽可能最好的解决方案。如果我们在流上添加规则(例如“在所有其他关系操作之前执行联接操作”),那么它也会减少很多可能性。
对于非常大的查询或具有非常快的答案(但不是非常快的查询)的情况,则使用另一种算法,即贪婪算法。这个想法是遵循规则(或启发式)以增量方式构建查询计划。使用此规则,贪婪算法一次找到一个问题的最佳解决方案。该算法从一个JOIN开始查询计划。然后,在每个步骤中,算法都会使用相同的规则将新的JOIN添加到查询计划中。
假设我们有一个查询,其中包含5个表(A,B,C,D和E)上的4个联接。为了简化问题,我们仅将嵌套联接作为可能的联接。让我们使用“使用成本最低的联接”规则。任意从5个表之一开始(让我们选择A),用A来计算每次连接的成本(A是内部或外部关系)。会发现A JOIN B成本最低,然后使用A JOIN B(A JOIN B是内部或外部关系)的结果来计算每个连接的成本,(A JOIN B)JOIN C提供了最佳成本,然后使用(A JOIN B)JOIN C的结果来计算每个联接的成本,最后我们找到了计划((((A JOIN B)JOIN C)JOIN D)JOIN E)。
由于我们从A任意开始,因此我们可以对B,C,D,E都应用相同的算法。然后以最低的成本保留计划。对于完整的动态编程版本,该算法的成本为O(N * log(N))对O(3 N)。如果你有20个联接的大型查询,则意味着26 vs 3 486 784 401。
该算法的问题在于,如果我们保持此联接并添加新联接,则假定在2个表之间找到最佳联接将为我们带来最佳成本。但:即使A JOIN B给出了A,B和C之间的最佳成本,(A JOIN C)JOIN B可能比(A JOIN B)JOIN C更好的结果。为了改善结果,你可以使用不同的规则运行多种贪婪算法,并保持最佳计划。
资料管理员
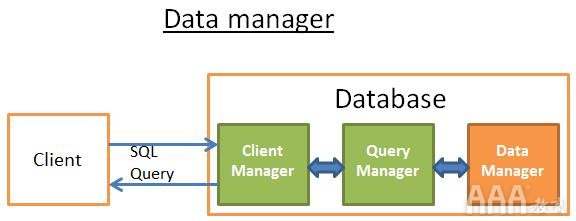
在此步骤中,查询管理器正在执行查询,并且需要表和索引中的数据。它要求数据管理器获取数据,但是有两个问题:
关系数据库使用事务模型。因此,你无法随时获取任何数据,因为其他人可能会同时使用/修改数据。
数据检索是数据库中最慢的操作,因此数据管理器必须足够聪明才能获取并将数据保留在内存缓冲区中。
在这一部分中,我们将看到关系数据库如何处理这两个问题。我不会谈论数据管理器获取数据的方式,因为它不是最重要的(本文足够长!)。
缓存管理器
正如我已经说过的,数据库的主要瓶颈是磁盘I / O。为了提高性能,现代数据库使用高速缓存管理器。
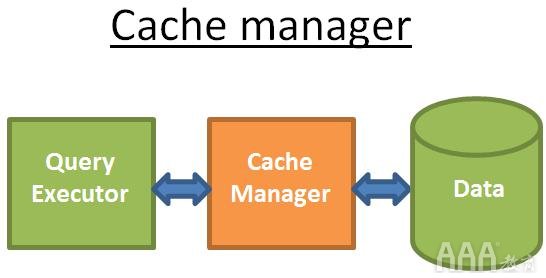
查询执行程序不是直接从文件系统获取数据,而是向高速缓存管理器请求数据。高速缓存管理器具有一个称为缓冲池的内存中高速缓存。从内存中获取数据极大地加快了数据库的速度。很难给出一个数量级,因为它取决于你需要执行的操作:
顺序访问(例如:全面扫描)与随机访问(例如:按行ID进行访问);读与写;数据库使用的磁盘类型:7.2k / 10k / 15k rpm硬盘,固态硬盘,RAID 1/5 /…内存比磁盘快100到10万倍会导致另一个问题。高速缓存管理器需要在查询执行程序使用它们之前获取内存中的数据。否则查询管理器必须等待慢速磁盘中的数据。此问题称为预取。查询执行器知道它需要的数据,因为它知道查询的全部流程,并且知道具有统计信息的磁盘上的数据。
当查询执行程序正在处理其第一堆数据时,它要求缓存管理器预加载第二组数据,当它开始处理第二组数据时,它要求CM预加载第三束,并通知CM可以从缓存中清除第一束。CM将所有这些数据存储在其缓冲池中。为了知道是否仍然需要数据,缓存管理器添加了有关缓存数据的额外信息(称为闩锁)。
有时查询执行器不知道需要什么数据,而某些数据库不提供此功能。取而代之的是,他们使用推测性预取或顺序预取。为了监视预取的工作状况,现代数据库提供了一个称为“缓冲区/缓存命中率”的指标。命中率显示在不要求磁盘访问的情况下在缓冲区高速缓存中找到请求数据的频率。
但是,缓冲区是有限的内存量。因此,它需要删除一些数据才能加载新数据。加载和清除缓存在磁盘和网络I / O方面要付出一定的代价。如果你有一个经常执行的查询,则始终加载然后清除此查询使用的数据并不是很有效。为了解决此问题,现代数据库使用缓冲区替换策略。
缓冲区替换策略
大多数现代数据库(至少是SQL Server,MySQL,Oracle和DB2)都使用LRU算法。
LRU
LRU代表大号东- [R ecently ü sed的。该算法的思想是将最近使用过的数据保存在缓存中,因此更有可能再次使用。
这是一个视觉示例:

在这个简单的示例中,缓冲区可以存储3个元素:
1:缓存管理器使用数据1并将数据放入空缓冲区
2:CM使用数据4并将数据放入半装入的缓冲区
3:CM使用数据3并将数据放入半载缓冲区
4:CM使用数据9。缓冲区已满,因此数据1被删除, 因为它是最近使用的数据。数据9被添加到缓冲区中
5:CM使用数据4。数据4已在缓冲区中,因此它再次成为最近使用的第一个数据。
6:CM使用数据1。缓冲区已满,因此数据9被删除, 因为它是最近使用的数据。数据1被添加到缓冲区
…
该算法效果很好,但存在一些局限性。如果在一张大桌子上进行全面扫描怎么办?换句话说,当表/索引的大小大于缓冲区的大小时会发生什么?使用此算法将删除高速缓存中的所有先前值,而完全扫描中的数据可能仅使用一次。
权重是使用数据的次数,如果将一堆新数据加载到缓存中,则不会删除旧的但经常使用的数据(因为它们的权重更高)。但是,如果不再使用旧数据,该算法便无法将其保留在缓存中。因此,如果不使用数据,权重会随着时间的推移而降低。
权重的计算成本很高,这就是为什么SQL Server仅使用K = 2的原因。该值在可接受的开销下表现良好。要更深入地了解LRU-K,可以阅读原始研究论文(1993年):用于数据库磁盘缓冲的LRU-K页面替换算法。
当然,还有其他算法可以管理缓存,例如
2Q(类似于LRU-K的算法)
时钟(类似于LRU-K的算法)
MRU(最近使用,使用与LRU相同的逻辑,但使用另一条规则)
LRFU(最近和经常使用的最少)
一些数据库允许使用默认算法以外的其他算法。写缓冲区:在数据库中,你还拥有写缓冲区,用于存储数据并将数据按束刷新到磁盘上,而不是一一写入数据并产生许多单个磁盘访问权限。
缓冲区存储的是页面(数据的最小单位)而不是行(这是查看数据的逻辑/人为方式)。如果页面已被修改且未写入磁盘,则缓冲池中的页面是脏的。有多种算法可以决定在磁盘上写入脏页的最佳时间,但是它与事务的概念高度相关。
ACID事务是确保以下四件事的工作单元:
原子性:即使持续10小时,交易还是“全有还是全无”。如果事务崩溃,则状态返回到事务之前(事务回滚)。
隔离度:如果2个事务A和B同时运行,则无论A在事务B之前/之后还是期间完成,事务A和B的结果都必须相同。
持久性:提交事务(即成功结束)后,无论发生什么情况(崩溃或错误),数据都会保留在数据库中。
一致性:仅将有效数据(就关系约束和功能约束而言)写入数据库。一致性与原子性和隔离性有关。

在同一事务中,你可以运行多个SQL查询来读取,创建,更新和删除数据。当两个事务使用相同的数据时,混乱就开始了。经典示例是从帐户A到帐户B的资金转帐。假设你有2笔交易:
交易1从帐户A收取100 $,并将其转入帐户B;交易2从帐户A收取50 $,并将其转入帐户B。
如果我们回到ACID属性:
原子性确保无论在T1期间发生什么情况(服务器崩溃,网络故障...),你都不会遇到从A撤回100 $而没有给B的情况(这种情况是不一致的) 。
I solation确保如果T1和T2同时发生,最终A将被收取150 $,B被给予150 $,而不是,例如,A会被收取150 $,而B仅被给予$ 50,因为T2已部分删除了操作T1的状态(这种情况也是不一致的状态)。
持久性可确保如果T1提交后数据库崩溃,T1将不会消失。
一致性确保不会在系统中创建或销毁任何资金。
大多数数据库都添加了自己的自定义隔离级别(例如PostgreSQL,Oracle和SQL Server使用的快照隔离)。而且,大多数数据库并没有实现SQL规范的所有级别(尤其是读取未提交的级别)。
用户/开发人员可以在连接开始时覆盖默认的隔离级别(这是添加的非常简单的代码行)。
并发控制
确保隔离,一致性和原子性的真正问题是对同一数据的写操作(添加,更新和删除):
如果所有事务都仅读取数据,则它们可以在不修改另一事务行为的情况下同时工作。
如果(至少)一个事务正在修改其他事务读取的数据,则数据库需要找到一种对其他事务隐藏此修改的方法。此外,还需要确保不会被其他未看到修改后的数据的事务擦除此修改。
此问题称为并发控制。
解决此问题的最简单方法是一个接一个地(即顺序地)运行每个事务。但这根本不是可扩展的,并且只有一个内核在多处理器/内核服务器上工作,效率不是很高……
解决此问题的理想方法是每次创建或取消交易时:监视所有交易的所有操作;检查两个(或多个)交易的部分是否存在冲突,因为它们正在读取/修改相同的数据;对冲突事务中的操作进行重新排序以减小冲突部分的大小;以一定顺序执行冲突部分(非冲突事务仍在并发运行)。
锁管理器:为了解决此问题,大多数数据库都使用锁和/或数据版本控制。
悲观锁定
锁定背后的想法是:如果交易需要数据,它锁定数据如果另一笔交易也需要此数据,它必须等到第一个事务释放数据。这称为排他锁。但是,对于仅需要读取数据的事务使用排他锁非常昂贵,因为它会强制其他只希望读取相同数据的事务等待。这就是为什么还有另一种类型的锁,即共享锁。
使用共享锁:如果交易只需要读取数据A,它“共享锁定”数据并读取数据,如果第二笔交易也只需要读取数据A;它“共享锁定”数据并读取数据,如果第三笔交易需要修改数据A,它“独占锁定”数据,但它必须等到其他2个事务释放它们的共享锁后才能将独占锁定应用于数据A。尽管如此,如果将数据作为排他锁,则仅需要读取数据的事务将不得不等待排他锁的结尾才能在数据上放置共享锁。
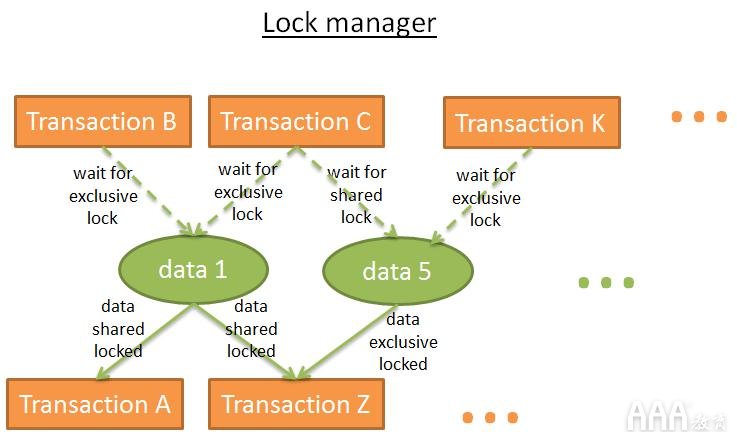
锁管理器是提供和释放锁的过程。在内部,它将锁存储在哈希表中(其中的键是要锁定的数据),并知道每个数据:哪些事务锁定了数据,哪些事务正在等待数据。
但是使用锁可能会导致2个事务永远等待数据的情况:
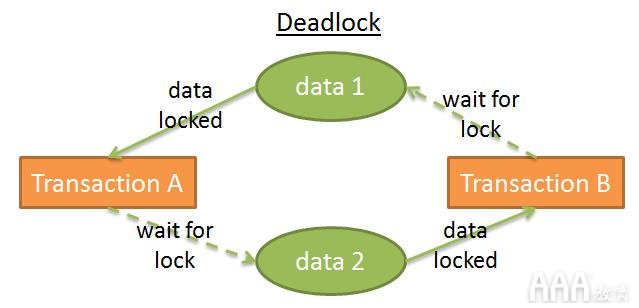
在此图中:
事务A拥有对data1的排他锁,正在等待获取data2;事务B在data2上具有排他锁,并且正在等待获取data1,这称为死锁。
在死锁期间,锁管理器选择要取消(回滚)的事务以删除死锁。这个决定并不容易:是否最好杀死修改了最少数据量的事务(因此将产生最便宜的回滚)?最好是因为另一笔交易的用户等待了更长的时间而取消了最老的交易?是否最好取消将花费较少时间完成的交易(并避免可能的饥饿)?如果发生回滚,此回滚将影响多少交易?但是在做出选择之前,它需要检查是否存在死锁。
哈希表可以看作是一个图形(就像前面的图中一样)。如果图中存在周期,则存在死锁。由于检查周期非常昂贵(因为带有所有锁的图相当大),因此通常使用一种更简单的方法:使用timeout。如果在此超时时间内未给出锁定,则事务将进入死锁状态。
锁管理器还可以在提供锁之前检查该锁是否会产生死锁。但是,完美地做到这一点在计算上又很昂贵。因此,这些预检查通常是一组基本规则。
两相锁定
确保纯隔离的最简单方法是在事务开始时获取锁,然后在事务结束时释放锁。这意味着事务必须在开始之前等待所有锁,并且在事务结束时释放由事务持有的锁。它可以工作,但 会浪费大量时间来等待所有锁。
更快的方法是两阶段锁定协议(DB2和SQL Server使用),该协议将事务分为两个阶段:
事务可以获取锁,但不能释放任何锁的增长阶段。
在收缩阶段,事务可以释放锁(针对已经处理并且不会再次处理的数据),但是无法获得新的锁。
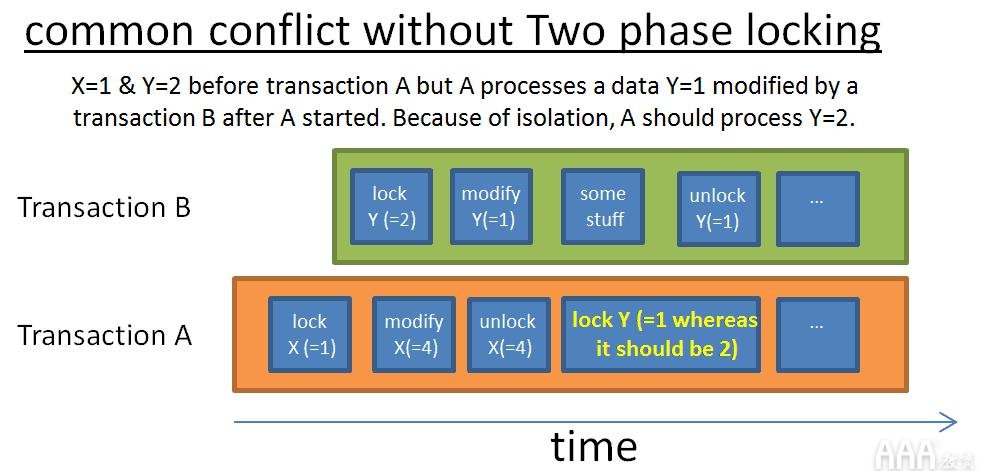
这两个简单规则的思想是:
释放不再使用的锁,以减少等待这些锁的其他事务的等待时间,以防止在交易开始后交易会修改数据并因此与交易获取的第一个数据不一致的情况。该协议运行良好,除非修改(取消)了修改数据并释放关联锁的事务。你可能最终遇到另一个事务读取修改后的值而该值将被回滚的情况。为避免此问题,必须在事务结束时释放所有排他锁。
当然,实际的数据库使用的是更复杂的系统,其中涉及更多类型的锁(例如意图锁)和更多的粒度(行,页面,分区,表,表空间上的锁),但是这种想法仍然存在相同的。
版本控制的思想是:每个交易都可以同时修改相同的数据;每笔交易都有其自己的数据副本(或版本)。
如果2个事务修改了相同的数据,则仅接受一个修改,而另一个则被拒绝,并且关联的事务将回滚(并可能重新运行)。由于以下原因,它提高了性能:读者交易不会阻止作家交易,作家交易不会阻止读者交易“胖而慢”的锁管理器没有任何开销。
一切都比锁好,除非两个事务写入相同的数据。此外,你可能很快就会面临巨大的磁盘空间开销。
数据版本控制和锁定是两个不同的愿景:乐观锁定与悲观锁定。他们都有优点和缺点;这实际上取决于用例(更多的读取还是更多的写入)。
某些数据库,例如DB2(直到DB2 9.7)和SQL Server(快照隔离除外)仅使用锁。其他类似PostgreSQL,MySQL和Oracle的混合方法涉及锁和数据版本控制。
版本控制会对索引产生有趣的影响:有时,唯一索引包含重复项,索引所包含的条目可能比表中具有行的条目多,等等。
如果阅读有关隔离级别不同的部分,则增加隔离级别时会增加锁的数量,因此事务等待其锁所浪费的时间。这就是为什么大多数数据库默认情况下不使用最高隔离级别(可序列化)的原因。
为了提高性能,数据库将数据存储在内存缓冲区中。但是,如果在提交事务时服务器崩溃,则崩溃期间你仍然会丢失仍在内存中的数据,这将破坏事务的持久性。你可以将所有内容写在磁盘上,但是如果服务器崩溃,最终将一半的数据写在磁盘上,这将破坏事务的原子性。
事务编写的任何修改必须撤消或完成。要解决此问题,有两种方法:
卷影副本/页面:每个事务都会创建自己的数据库副本(或只是数据库的一部分)并在此副本上工作。万一出错,副本将被删除。如果成功,数据库将使用文件系统技巧立即从副本切换数据,然后删除“旧”数据。
事务日志:事务日志是一个存储空间。在每次将磁盘写入磁盘之前,数据库都会在事务日志上写入信息,以便在事务崩溃/取消的情况下,数据库知道如何删除(或完成)未完成的事务。
当在涉及许多事务的大型数据库上使用时,卷影副本/页面会产生巨大的磁盘开销。这就是为什么现代数据库使用事务日志的原因。事务日志必须存储在稳定的存储器中。我不会更深入地介绍存储技术,但是必须(至少)使用RAID磁盘来防止磁盘故障。
大多数数据库(至少是Oracle,SQL Server,DB2,PostgreSQL,MySQL和 SQLite)都使用预写日志记录协议(WAL)处理事务日志。WAL协议是3条规则的集合:
1)对数据库的每次修改都会产生一个日志记录,并且在将数据写入磁盘之前,必须将日志记录写入事务日志中。
2)日志记录必须按顺序写入;在必须在日志记录B之前但在B之前写入的日志记录A
3)提交事务后,必须在事务成功结束之前将提交顺序写在事务日志上。

这项工作由日志管理器完成。在完成所有工作之后,你应该知道与数据库相关的所有内容都受到“数据库效应”的诅咒。更严重的是,问题是找到一种在保持良好性能的同时写入日志的方法。如果事务日志上的写入太慢,它们将减慢所有操作。
数据库必须回滚事务有多种原因:因为用户取消了,由于服务器或网络故障,因为事务破坏了数据库的完整性(例如,你对列具有UNIQUE约束,并且事务添加了重复项)。
事务期间的每个操作(添加/删除/修改)都会生成一个日志。该日志记录由以下内容组成:
LSN:一个独特的大号OG小号层序Ñ棕土。该LSN按时间顺序给出*。这意味着,如果操作A在操作B之前发生,则日志A的LSN将低于日志B的LSN。
TransID:产生该操作的事务的ID。
PageID:修改后的数据在磁盘上的位置。磁盘上的最小数据量是一个页面,因此数据的位置就是包含该数据的页面的位置。
PrevLSN:指向同一事务产生的先前日志记录的链接。
撤消操作:消除操作影响的一种方法
例如,如果操作是更新,则UNDO将存储更新之前的更新元素的值/状态(物理UNDO),或者存储反向操作以返回到先前状态(逻辑UNDO)**。
REDO:重播操作的一种方式
同样,有两种方法可以做到这一点。你可以在操作之后存储元素的值/状态,或者在操作本身中存储元素以重播它。
此外,磁盘上的每个页面(用于存储数据,而不是日志)具有修改数据的最后操作的日志记录(LSN)的ID。
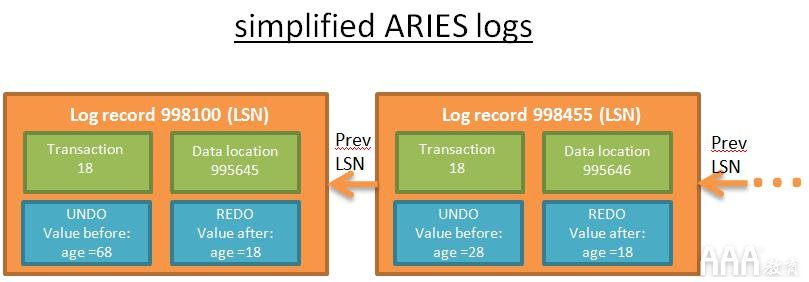
每个日志都有一个唯一的LSN。链接的日志属于同一事务。日志按时间顺序链接(链接列表的最后一个日志是最后一个操作的日志)。为避免日志写入成为主要瓶颈,使用了日志缓冲区。
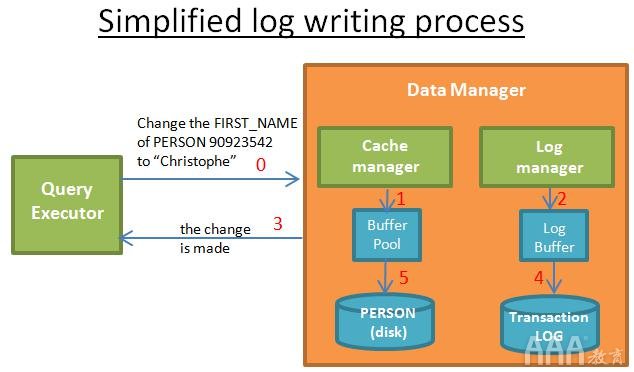
当查询执行者要求修改时:
1)缓存管理器将修改存储在其缓冲区中。
2)日志管理器将关联的日志存储在其缓冲区中。
3)在这一步,查询执行者认为操作已完成(因此可以要求其他修改)
4)然后(稍后),日志管理器将日志写入事务日志中。何时写入日志的决定是由算法完成的。
5)然后(稍后),缓存管理器将修改内容写入磁盘。何时将数据写入磁盘的决定是由算法决定的。
提交事务后,这意味着对于事务中的每个操作,都将完成步骤1、2、3、4、5。写入事务日志的速度很快,因为它只是“在事务日志中的某处添加日志”,而将数据写入磁盘则更为复杂,因为它是“以快速读取数据的方式写入数据”。
窃取和强制政策
出于性能原因,可能在提交后执行步骤5,因为如果发生崩溃,仍然可以使用REDO日志恢复事务。这就是所谓的NO-FORCE政策。
数据库可以选择一个FORCE策略(即,必须在提交之前执行步骤5),以降低恢复过程中的工作量。
另一个问题是选择是将数据逐步写入磁盘(STEAL策略),还是选择缓冲区管理器是否需要等到提交顺序一次写入所有内容(NO-STEAL)。在STEAL和NO-STEAL之间进行选择取决于你想要的:使用UNDO日志进行长时间恢复的快速写入还是快速恢复?
STEAL / NO-FORCE 需要UNDO和REDO:最高的性能,但提供更复杂的日志和恢复过程(如ARIES)。这是大多数数据库所做的选择。
STEAL / FORCE仅需要撤消;无需窃取/无需强制只需要重做;无窃取/强制不需任何东西:最差的性能和大量的夯是必需的。
ARIES通过以下三步从崩溃中恢复:
1)分析阶段:恢复过程读取完整的事务日志*,以重新创建崩溃期间发生的事情的时间表。它确定要回滚的事务(所有没有提交订单的事务都将回滚)以及崩溃时需要将哪些数据写入磁盘。
2)重做过程:此过程从分析期间确定的日志记录开始,并使用REDO将数据库更新为崩溃前的状态。
在重做阶段,将按时间顺序(使用LSN)处理REDO日志。
对于每个日志,恢复过程都会读取磁盘上包含要修改的数据的页面的LSN。
如果LSN(page_on_disk)> = LSN(log_record),则意味着数据已在崩溃之前被写入磁盘(但是该值已被日志之后和崩溃之前发生的操作所覆盖),因此什么也不做。
如果LSN(page_on_disk)
即使对于将要回滚的事务,重做也已完成,因为它简化了恢复过程(但我敢肯定,现代数据库不会这样做)。
3)撤消密码:此密码会回退崩溃时所有未完成的事务。回滚从每个事务的最后一个日志开始,并以反时间顺序(使用日志记录的PrevLSN)处理UNDO日志。
在恢复期间,必须警告事务日志有关恢复过程所执行的操作,以便磁盘上写入的数据与事务日志中写入的数据同步。一种解决方案是删除正在撤消的事务的日志记录,但这非常困难。而是,ARIES将补偿日志写入事务日志中,该日志将逻辑上删除要删除的事务的日志记录。
当“手动”取消交易或由锁定管理器取消交易(以停止死锁)或仅由于网络故障而取消交易时,则不需要分析通过。实际上,有关REDO和UNDO内容的信息可在2个内存表中找到:
一个事务表(存储所有当前事务的状态)
一个脏页表(需在磁盘上写入数据需要存储)。
这些表由缓存管理器和事务管理器针对每个新事务事件进行更新。由于它们在内存中,因此在数据库崩溃时会被销毁。
分析阶段的工作是在崩溃后使用事务日志中的信息重新创建两个表。*为了加快分析过程,ARIES提供了checkpoint的概念。想法是不时在磁盘上写入事务表,脏页表的内容以及该写入时的最后LSN的内容,以便在分析过程中仅分析此LSN之后的日志。
当你不得不在错误的NoSQL数据库和坚如磐石的关系数据库之间进行选择时,请三思而后行。有些NoSQL数据库很棒。但是他们还很年轻,正在回答涉及一些应用程序的特定问题。
经过以上了解,大家应该明白大数据中数据库是如何工作的了,想要学习更深层次的大数据专业知识,可以到AAA教育官网了解一下,大数据分析专业,互联网热门行业,技术含量高,无论是找工作还是自我提升都是不错的选择。
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 大数据中数据库是如何工作的
- 数据库是如何工作的