



大数据分析如何使用Python进行自然语言处理
2020-10-16
点击量:次
Python具有一些强大的工具,使您能够执行自然语言处理(NLP)。在大数据分析如何使用Python进行自然语言处理中,我们将学习如何在Python中执行一些基本的NLP。
看数据
我们将查看一个数据集,该数据集包括2006年至2015年间向Hacker News提交的内容。数据取自此处。Arnaud Drizard使用Hacker News API进行了抓取。我们10000从数据中随机采样了行,并删除了所有多余的列。我们的数据只有四列:
1)submission_time -故事提交时。
2)url —提交的基本URL。
3)upvotes -提交的投票数。
4)headline —提交的标题。
我们将使用头条新闻来预测投票数。数据存储在submissions变量中。
自然语言处理-第一步
我们最终希望训练一种机器学习算法,使其成为标题,并告诉我们它将获得多少票。但是,机器学习算法只能理解数字,而不能理解单词。我们如何将标题转换为算法可以理解的内容?
第一步是创建一个称为单词袋矩阵的东西。一袋单词矩阵给我们一个数字表示哪个单词在哪个标题中。为了构建单词袋矩阵,我们首先在整个标题中找到唯一的单词。然后,我们建立一个矩阵,其中每一行都是标题,每一列都是唯一的单词之一。然后,我们用单词在该标题中出现的次数填充每个单元格。这将导致一个矩阵,其中的许多单元格的值为零,除非词汇在标题之间大部分是共享的。
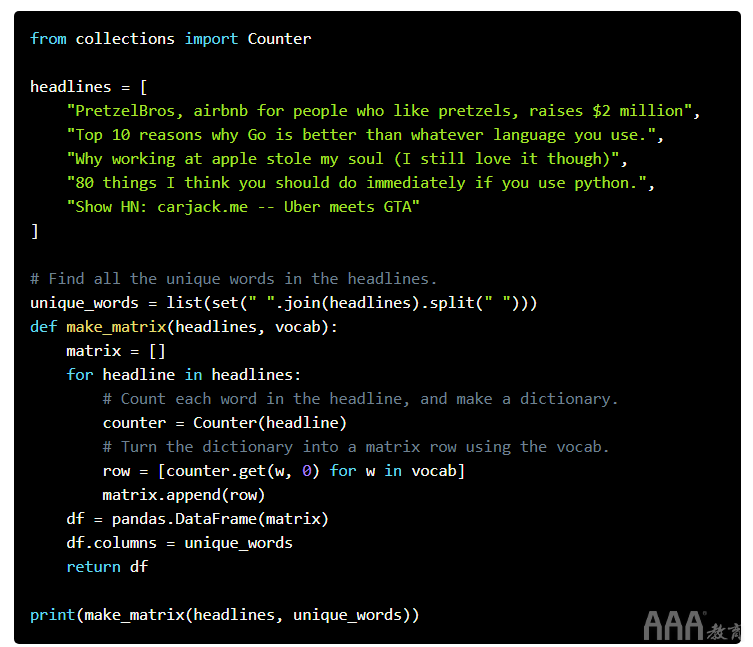
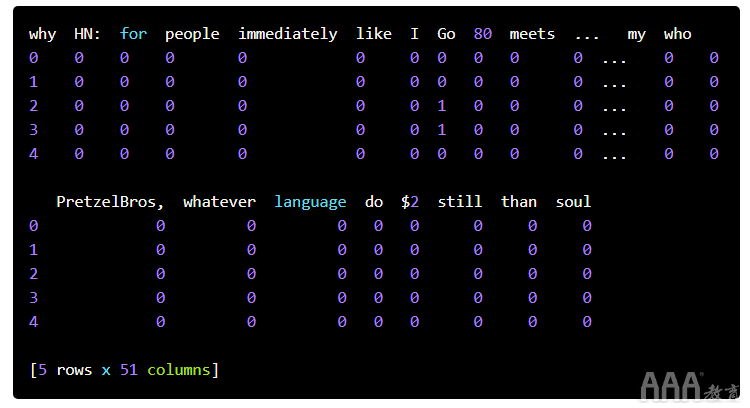
删除标点符号
我们刚刚制作的矩阵非常稀疏-这意味着很多值都是零。在一定程度上这是不可避免的,因为标题没有太多共享的词汇。不过,我们可以采取一些措施来改善问题。目前,Why和why,和use和use.被视为不同的实体,但是我们知道它们指的是相同的词。我们可以通过简化每个单词并删除所有标点符号来帮助解析器认识到它们实际上是相同的。
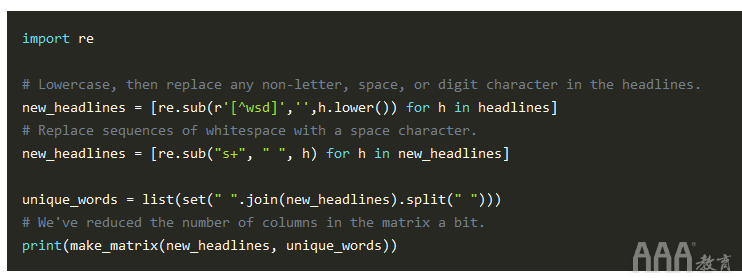
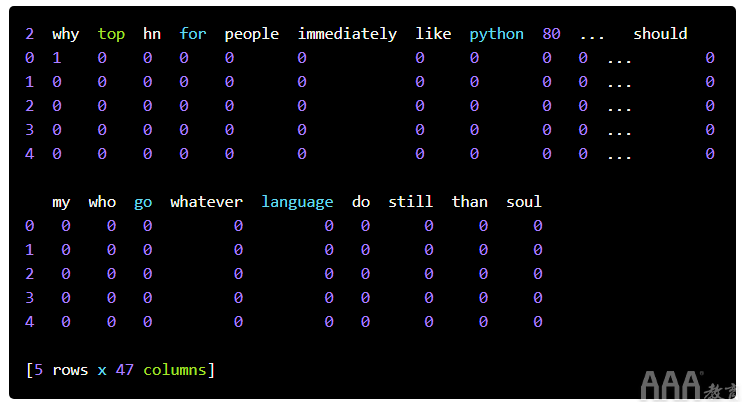
删除停用词
某些字词无法帮助您区分好坏标题。词语,例如the,a和also发生通常足以在所有上下文中,他们没有真正告诉我们很多关于什么是好还是不好。它们通常同样有可能同时出现在头条新闻和头条新闻中。通过删除这些,我们可以减小矩阵的大小,并使训练算法更快。
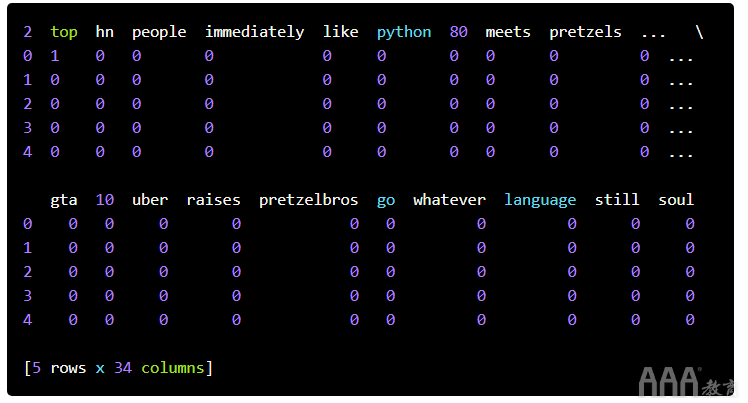
生成所有标题的矩阵
现在我们已经了解了基础知识,我们可以为整个标题制作一袋单词矩阵。我们不需要每次都手动编写所有代码,因此我们将使用scikit-learn中的类来自动执行。使用scikit-learn的矢量化器来构造您的单词矩阵包将使此过程变得更加轻松和快捷。
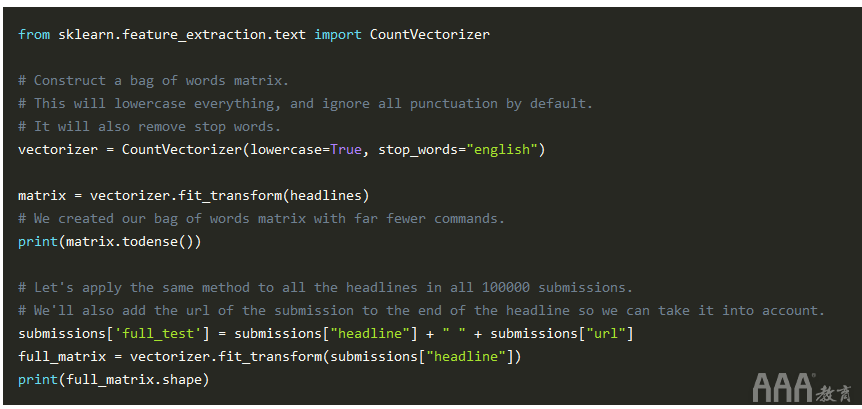

减少尺寸
我们已经构造了一个矩阵,但是它现在具有13631唯一的单词或列。进行预测将花费很长时间。我们想加快速度,因此我们需要以某种方式减少列数。一种方法是从信息量最大的列中选择一个子集,也就是,区分好和坏标题的列是最好的。
找出信息最多的列的一种好方法是使用一种称为卡方检验的方法。卡方检验可发现在高度赞同的帖子和未赞同的帖子之间区别最大的单词。这可能是在高评价的帖子中经常出现的单词,而在没有高评价的帖子中根本没有出现,或者在没有高评价的帖子中经常出现但在高评价的帖子中没有出现的单词。卡方检验仅适用于二进制值,因此我们将upvotes列设置为二进制,将upvotes高于平均值to的值设置为1up to0。缺点之一是,我们使用数据集中的知识来选择特征,从而引入一些过拟合。通过使用数据的一个子集进行特征选择,并使用另一个子集来训练算法,我们可以解决“现实世界”中的过度拟合问题。现在,我们将使事情变得更简单,然后跳过该步骤。
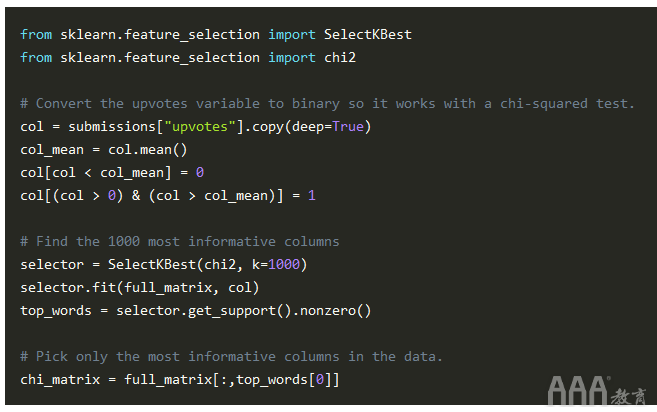
添加元功能
如果我们忽略标题的“元”功能,那么我们会丢失许多有用的信息。这些功能包括长度,标点数量,平均单词长度以及其他特定于句子的功能。添加这些可以大大提高预测准确性。要添加它们,我们将遍历标题,并对每个标题应用一个函数。一些功能将以字符为单位计算标题的长度,而其他功能将进行更高级的操作,例如计算数字位数。
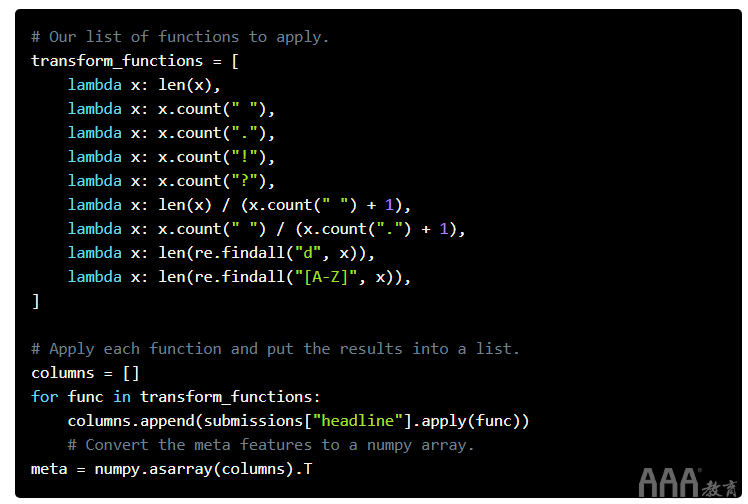
增加更多功能
我们可以使用的功能不仅仅是文字功能。我们有一个名为的列submission_time,它告诉我们故事提交的时间,并且可以添加更多信息。通常在进行NLP工作时,您将能够添加外部功能,从而使您的预测更好。一些机器学习算法可以弄清楚这些功能如何与您的文字功能进行交互(例如,“在午夜发布,标题中带有'tacos'的单词会获得较高的得分”)。
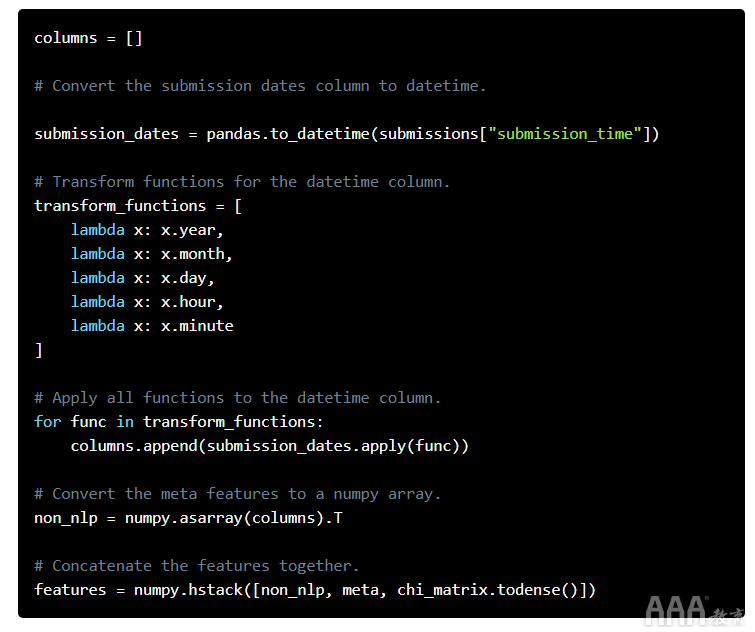
做出预测
现在我们可以将单词翻译为数字,可以使用算法进行预测了。我们将随机选择7500标题作为训练集,然后在2500标题测试集上评估算法的性能。在我们训练的同一集合上预测结果将导致拟合过度,这会导致您的算法针对训练集过度优化-我们认为错误率不错,但在新数据上实际上可能更高。对于算法,我们将使用岭回归。与普通的线性回归相比,岭回归对系数造成了损失,从而防止了系数变得太大。像我们一样,这可以帮助它处理大量相互关联的预测变量(列)。
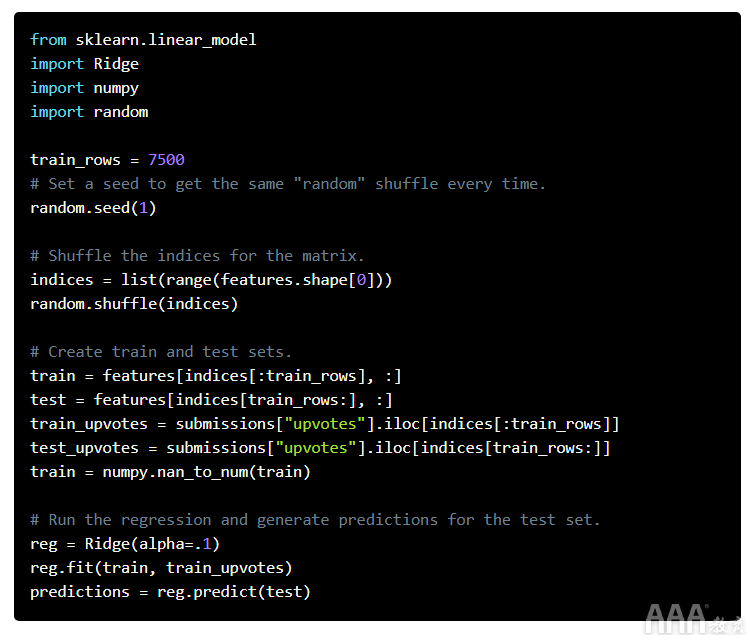
评估误差
现在我们有了预测,但是我们如何确定它们的好坏呢?一种方法是计算测试集预测与测试集实际投票数之间的错误率。我们还希望巴塞尔比较错误,以查看结果是否良好。为此,我们可以使用一种简单的方法为测试集进行基线估计,然后将预测的错误率与基线估计的错误率进行比较。
一个非常简单的基准是获取训练集中每个提交的平均投票数,并将其用作每个提交的预测。我们将使用平均绝对误差作为误差度量。这非常简单-只需从预测中减去实际值,取差的绝对值,然后找到所有差的平均值即可。
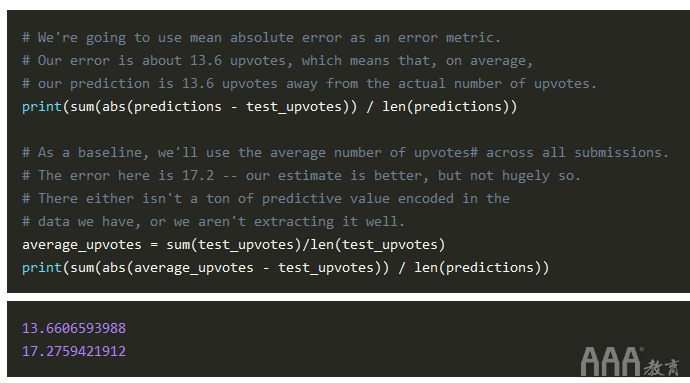
下一步
此方法在该数据集上合理有效,但效果并不理想。我们发现标题和其他列具有一定的预测价值。我们可以通过使用不同的预测算法(例如随机森林或神经网络)来改进此方法。在生成词袋矩阵时,我们也可以使用ngram,例如bigrams和trigram。
在矩阵上 尝试tf-idf转换也可能会有所帮助-scikit-learn有一个可自动执行此操作的类。我们还可以考虑其他数据,例如提交文章的用户,并生成指示诸如用户的业力和用户的近期活动之类的特征。有关已提交网址的其他统计信息(例如,从该网址收到的已提交upuptes的平均数量)也可能很有用。
进行这些操作时请务必谨慎,以仅考虑进行预测的提交之前存在的信息。所有这些添加都将比我们到目前为止花费更多的时间来运行,但是会减少错误。希望您有一些时间来尝试一下!如果您想与NLP合作,请查看我们的交互式《大数据分析课程》。
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 大数据分析如何使用Python进行自然语言处理
- 大数据分析