



如何将Excel和Python和Pandas结合使用
2020-10-06
点击量:次
如何将Excel和Python和Pandas结合使用?为什么要学习在Python中使用Excel? Excel是最流行和广泛使用的数据工具之一。很难找到一个不以某种方式与之合作的组织。从分析师到销售副总裁,再到首席执行官,各种专业人员都使用Excel进行快速统计和严重的数据处理。
随着Excel的普及,数据专业人员必须熟悉它。与Python的UI相比,使用Python或R处理数据具有明显的优势,因此找到一种使用代码使用Excel的方法至关重要。值得庆幸的是,已经有一个很棒的工具叫做,可以在Python中使用Excel pandas。
Pandas具有从Excel文件读取各种数据的出色方法。您也可以将结果从Pandas导出回Excel,如果您的目标受众更喜欢的话。Pandas非常适合其他常规数据分析任务,例如:
1)快速探索性数据分析(EDA)
2)绘制有吸引力的地块
3)将数据输入到scikit-learn等机器学习工具中
4)在数据上建立机器学习模型
5)将清理和处理过的数据带入任意数量的数据工具
Pandas在自动化数据处理任务方面比Excel更好,包括处理Excel文件。
在如何将Excel和Python和Pandas结合使用中,我们将向您展示如何使用Pandas中的Excel文件。我们将介绍以下概念。
1)使用必要的软件设置计算机
2)将数据从Excel文件读入Pandas
3)Pandas数据探索
4)使用matplotlib可视化库可视化Pandas中的数据
5)在Pandas中处理和重塑数据
6)将数据从Pandas移动到Excel
请注意,如何将Excel和Python和Pandas结合使用并未深入探讨Pandas。要进一步探索Pandas,请查看我们的课程。
系统先决条件
在如何将Excel和Python和Pandas结合使用中,我们将使用Python 3和Jupyter Notebook演示代码。
除了Python和Jupyter Notebook,您还将需要以下Python模块:
1)matplotlib –数据可视化
2)NumPy –数值数据功能
3)OpenPyXL –读/写Excel 2010 xlsx / xlsm文件
4)大Pandas–数据导入,清理,探索和分析
4)xlrd –读取Excel数据
5)xlwt –写入Excel
6)XlsxWriter –写入Excel(xlsx)文件
设置所有模块有多种方法。我们在下面介绍三种最常见的方案。
1)如果通过Anaconda软件包管理器安装了Python ,则可以使用以下命令安装所需的模块conda install。例如,要安装Pandas,您将执行命令– conda install pandas。
2)如果您已经在计算机上安装了常规的非Anaconda Python,则可以使用来安装所需的模块pip。打开命令行程序并执行命令pip install 以安装模块。您应该用要安装的模块的实际名称替换。例如,要安装Pandas,您将执行命令– pip install pandas。
3)如果尚未安装Python,则应通过Anaconda软件包管理器进行获取。Anaconda提供了适用于Windows,Mac和Linux计算机的安装程序。如果选择完整的安装程序,则将在一个软件包中获得所需的所有模块以及Python和pandas。这是最简单,最快的入门方法。
数据集
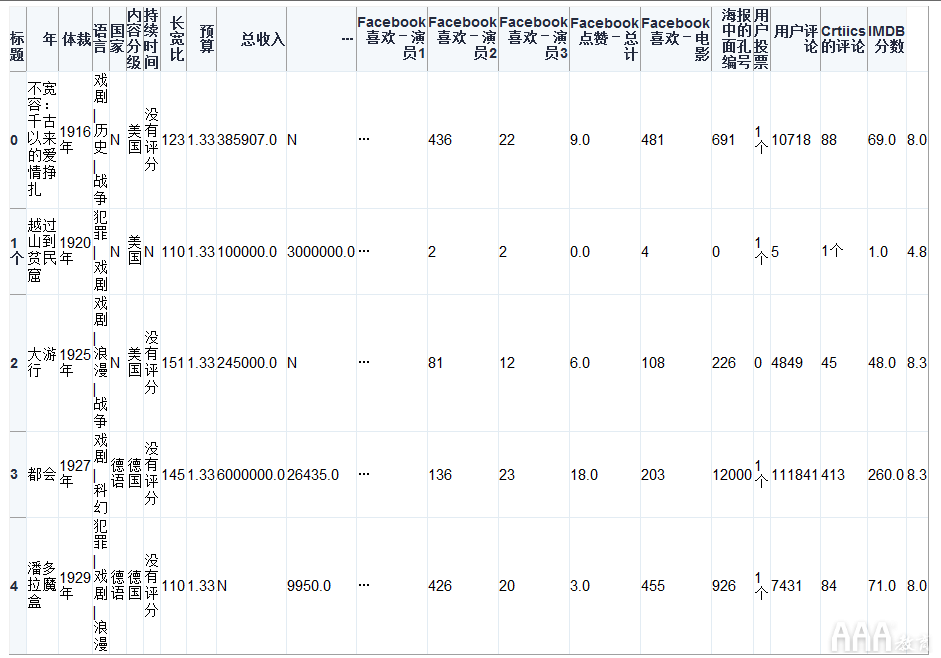
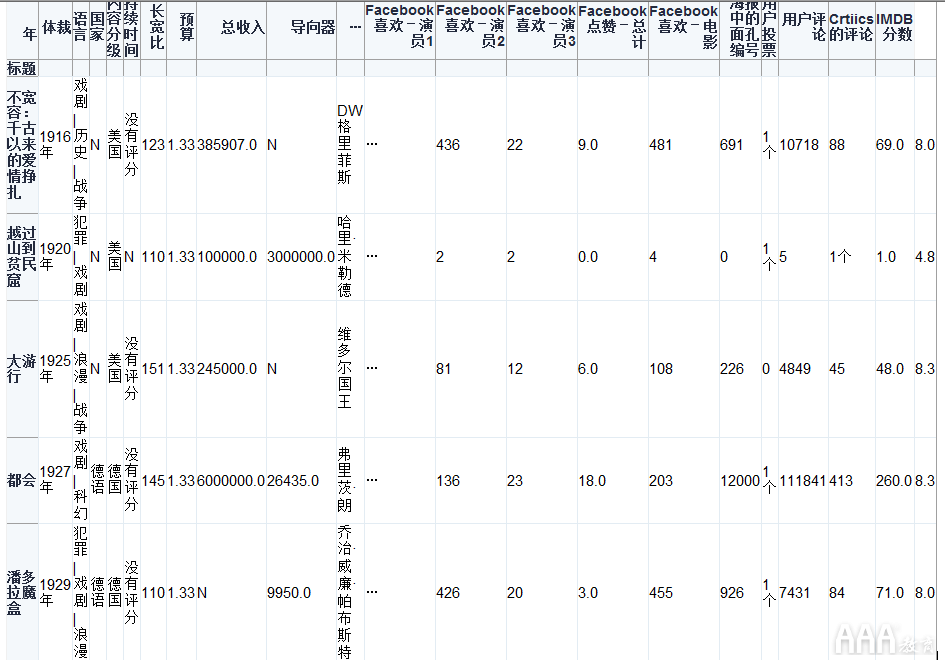
在如何将Excel和Python和Pandas结合使用中,我们将使用由Kaggle的IMDB分数数据创建的多页Excel文件。

我们的Excel文件分为三页:“ 1900年代”,“ 2000年代”和“ 2010年代”。每张纸都包含那几年的电影数据。
我们将使用此数据集来查找电影的收视率分布,可视化具有最高收视率和净收入的电影,并计算有关电影的统计信息。我们将使用Python和pandas分析和探索这些数据,从而展示pandas在Python中处理Excel数据的功能。
从Excel文件中读取数据
我们需要首先将数据从Excel文件导入到Pandas中。为此,我们首先导入pandas模块。

然后,我们使用Pandas的read_excel方法从Excel文件中读取数据。调用此方法的最简单方法是传递文件名。如果未指定工作表名称,则它将读取索引中的第一张工作表(如下所示)。

在此,该read_excel方法将数据从Excel文件读取到pandas DataFrame对象中。Pandas默认将数据存储在DataFrames中。然后,我们将此DataFrame存储到名为的变量中movies。
Pandas有一个内置DataFrame.head()方法,我们可以使用它轻松显示DataFrame的前几行。如果未传递任何参数,它将显示前五行。如果传递了一个数字,它将从顶部开始显示相等的行数。

Excel文件通常具有多个工作表,并且读取特定工作表或全部工作表的功能非常重要。为了简化此过程,pandasread_excel方法采用了一个称为的参数sheetname,该参数告诉pandas从数据中读取哪张纸。为此,您可以使用工作表名称或工作表编号。工作表编号从零开始。如果sheetname未提供参数,则默认为零,Pandas将导入第一张纸。
默认情况下,pandas将自动分配一个从零开始的数字索引或行标签。如果您的数据没有具有唯一值的列,可以用作更好的索引,则可能需要保留默认索引。如果您认为有一个列可以用作更好的索引,则可以通过将index_col属性设置为列来覆盖默认行为。它使用一个数值来将单个列设置为索引,或者使用数值列表来创建一个多索引。
在下面的代码中,我们通过将零传递给index_col参数来选择第一列“标题”作为索引(index = 0)。

如上所述,我们的Excel数据文件分为三页。我们已经阅读了上面的DataFrame中的第一张表。现在,使用相同的语法,我们还将阅读其余两页。

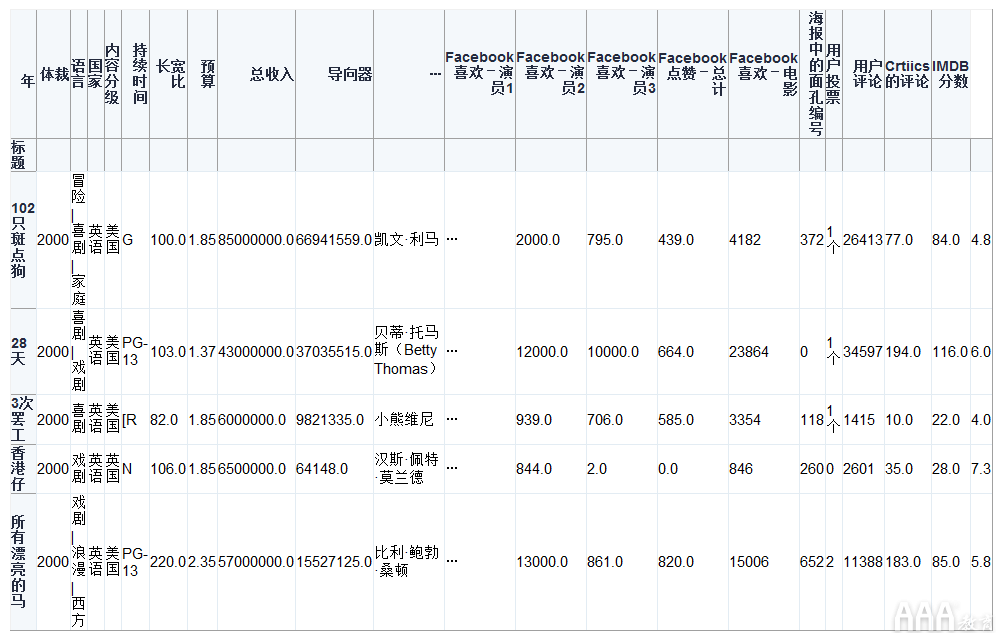

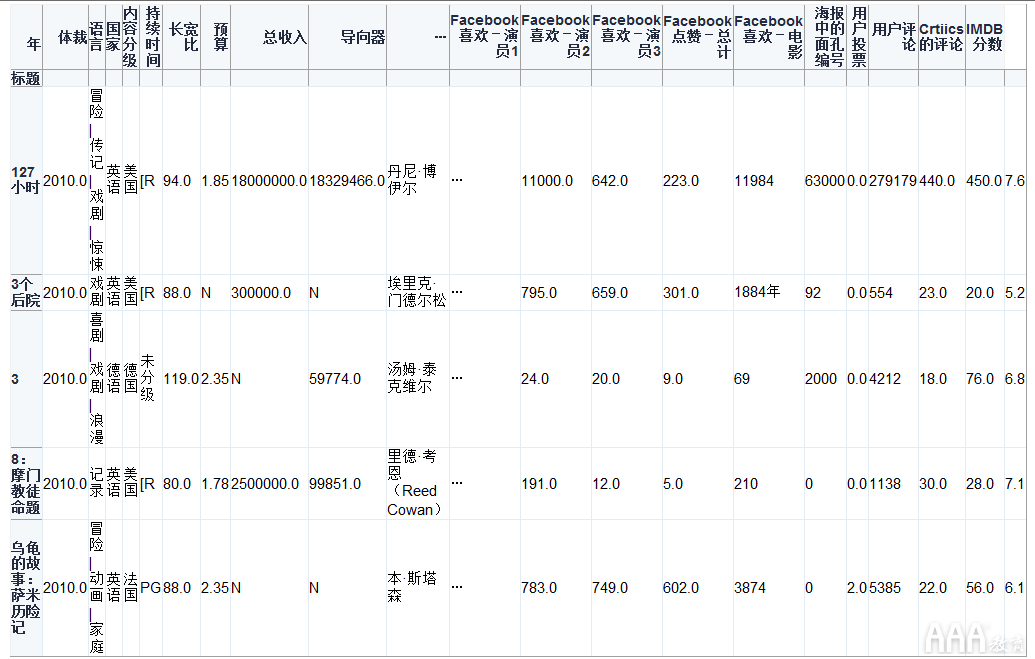
由于所有三个工作表都具有相似的数据,但记录运动不同,因此我们将根据上面创建的所有三个数据帧创建一个单独的数据帧。concat为此,我们将使用pandas方法,并传入刚刚创建的三个DataFrame的名称,并将结果分配给新的DataFrame对象movies。通过保持DataFrame名称与以前相同,我们将覆盖先前创建的DataFrame。

我们可以通过调用组合后的DataFrame中的行数来检查该串联,方法是调用组合后的DataFrame中的方法shape,该方法将为我们提供行数和列数。

使用ExcelFile类读取多张工作表
我们还可以使用ExcelFile类来处理来自同一Excel文件的多个工作表。我们首先使用来包装Excel文件ExcelFile,然后将其传递给read_excelmethod。
如果您正在阅读包含大量图纸的Excel文件并创建大量DataFrame,ExcelFile则与相比,它更加便捷高效read_excel。使用ExcelFile,您只需传递一次Excel文件,然后就可以使用它来获取DataFrame。使用时read_excel,您每次都会传递Excel文件,因此会为每张纸再次加载该文件。如果Excel文件中包含许多行数很多的工作表,这可能会极大地拖累性能。
探索数据
现在,我们已经从Excel文件中读取了电影数据集,我们可以开始使用Pandas进行探索了。大PandasDataFrame以表格格式存储数据,就像Excel在表格中显示数据的方式一样。Pandas有很多内置方法来探索我们从刚刚读入的Excel文件中创建的DataFrame。
我们已经head在上一节中介绍了该方法,该方法从DataFrame的顶部开始显示几行。让我们看看在探索数据集时会派上用场的其他几种方法。
我们可以使用该shape方法找出DataFrame的行数和列数。

这告诉我们我们的Excel文件具有5042条记录和25列或观察值。这对于报告记录和列的数量并将其与源数据集进行比较很有用。
我们可以使用该tail方法查看底部的行。如果未传递任何参数,则仅返回底部的五行。


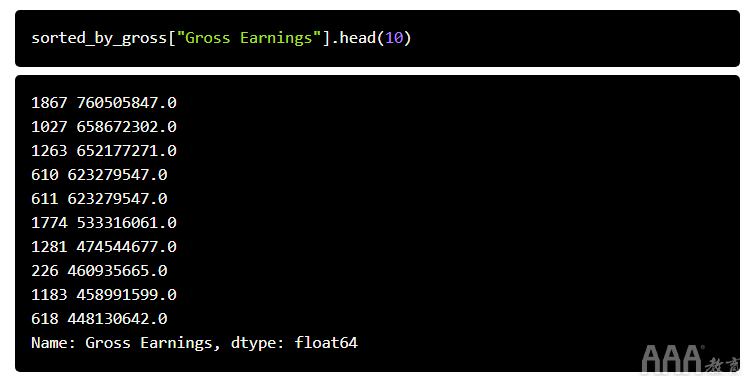
在Excel中,您可以根据一列或多列中的值对工作表进行排序。在Pandas中,您可以使用该sort_values方法执行相同的操作。例如,让我们根据“总收入”列对电影数据帧进行排序。

由于我们将数据按列中的值排序,因此我们可以做一些有趣的事情。例如,我们可以显示总收入前10名电影。
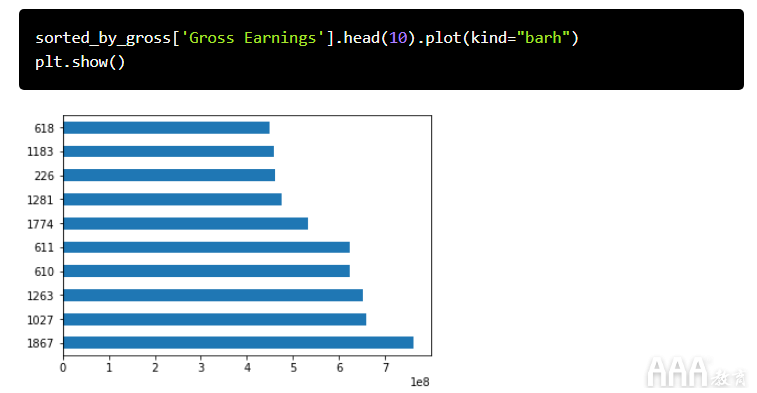
我们还可以为《总收入》中的前十部电影创建情节。通过流行的数据可视化库matplotlib,Pandas可以很容易地用绘图和图表可视化数据。用几行代码,您就可以开始绘图。此外,由于您可以在代码下直接放置图表,因此matplotlib图表在Jupyter Notebook中可以很好地工作。
首先,我们导入matplotlib模块并设置matplotlib以在Jupyter Notebook中直接显示图。

我们将绘制一个条形图,其中每个条形将代表前十部电影之一。为此,我们可以调用plot方法并将参数设置kind为barh。这告诉matplotlib您绘制水平条形图。
让我们创建一个IMDB分数的直方图,以检查IMDB分数在所有电影中的分布。直方图是可视化数据集分布的好方法。我们使用plot电影让我们创建一个IMDB分数的直方图,以检查IMDB分数在所有电影中的分布。直方图是可视化数据集分布的好方法。我们使用plot电影数据帧中IMDB Scores系列的方法,并将其传递给参数。数据帧中IMDB Scores系列的方法,并将其传递给参数。
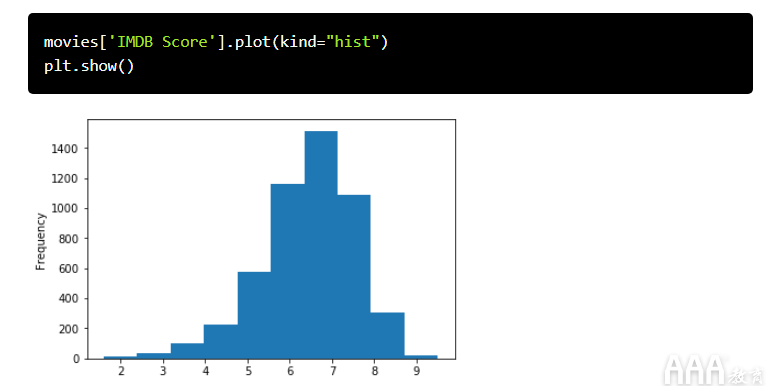
此数据可视化表明,大多数IMDB分数介于6到8之间。
获取有关数据的统计信息
Pandas有一些非常方便的方法来查看有关我们数据集的统计数据。例如,我们可以使用该describe方法来获取数据集的统计摘要。

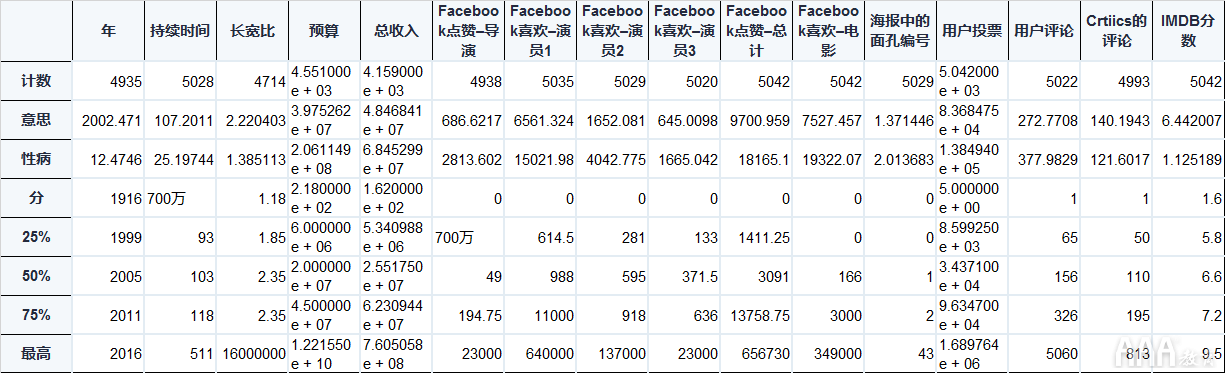
该describe方法为每个列显示以下信息。
1)值的数量或数量
2)意思
3)标准偏差
4)最小,最大
5)25%,50%和75%的分位数
请注意,此信息仅针对数字值进行计算。
我们还可以使用相应的方法一次访问此信息。例如,要获取特定列的均值,可以使用该mean列上的方法。

就像平均值一样,我们要访问的每种统计信息都有可用的方法。您可以在我们的免费Pandas备忘单上阅读有关这些方法的信息。
读取没有标题的文件并跳过记录
在如何将Excel和Python和Pandas结合使用的前面,我们看到了一些方法来读取一种特殊的Excel文件,该文件具有标题并且没有需要跳过的行。有时,Excel工作表没有任何标题行。对于此类情况,您可以告诉Pandas不要将第一行视为标题或列名。并且,如果Excel工作表的前几行包含不应读取的数据,则可以要求该read_excel方法从顶部开始跳过一定数量的行。
例如,查看此Excel文件的前几行。
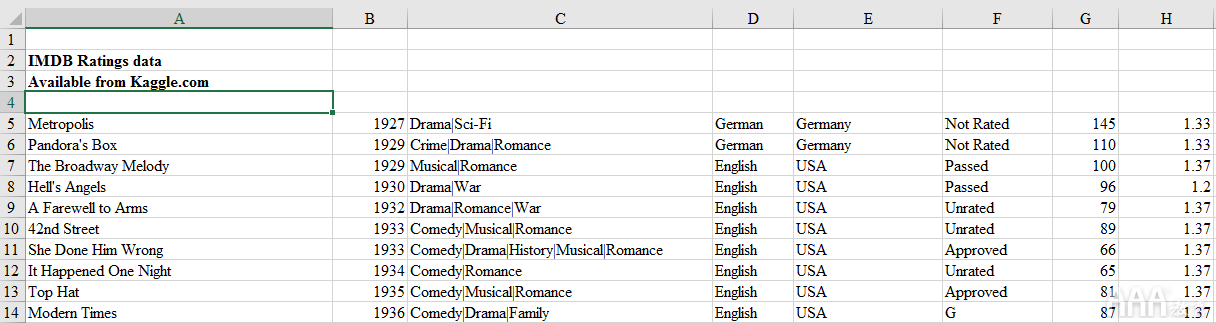
该文件显然没有标题,并且前四行不是实际记录,因此不应读入。通过将参数设置header为None,可以告诉read_excel没有标题,并且可以通过将参数设置skiprows为4来跳过前四行。
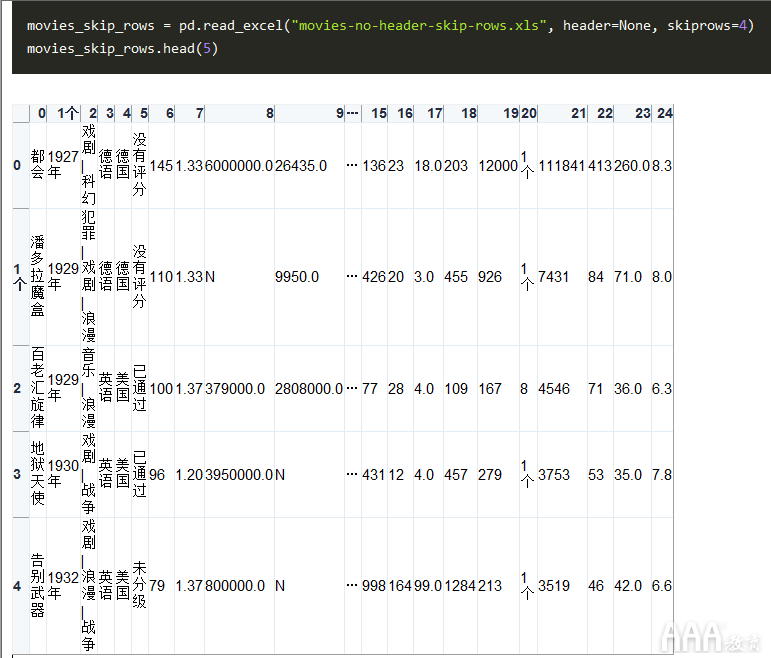

我们从工作表中跳过了四行,没有任何行用作标题。另外,请注意,可以在一个read语句中组合不同的选项。要跳过工作表底部的行,可以使用option skip_footer,它的作用与一样skiprows,唯一的区别是行是从底部向上计数的。
前一个DataFrame中的列名称是数字,并且由Pandas默认分配。通过columns在DataFrame上调用方法并将列名作为列表传递,我们可以将列名重命名为描述性名称。

现在,我们已经了解了如何从Excel文件读取行的子集,我们可以学习如何读取列的子集。
读取列的子集
尽管read_excel默认为读取和导入所有列,但是您可以选择仅导入某些列。通过传递parse_cols = 6,我们告诉该read_excel方法仅读取第一列,直到索引为六或前七个列(第一列的索引为零)。
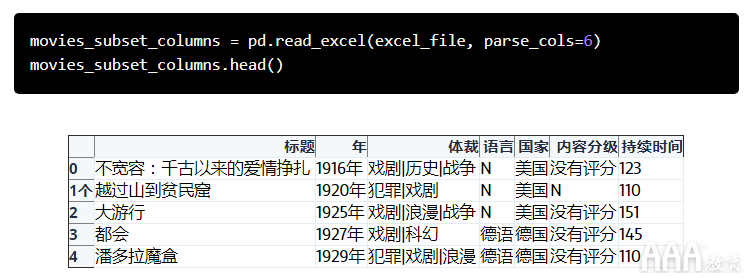
或者,您可以传入一个数字列表,这将使您可以导入特定索引处的列。
在列上应用公式
Excel的常用功能之一是应用公式从现有列值创建新列。在我们的Excel文件中,我们有“总收入”和“预算”列。我们可以通过从总收入中减去预算来获得净收入。然后,我们可以将此公式在Excel文件中应用于所有行。我们也可以在Pandas中做到这一点,如下所示。

上面,我们使用Pandas创建了一个名为“净收入”的新列,并在其中填充了“总收入”和“预算”的差额。值得注意的是,Excel和Pandas在公式处理方式上的区别。在Excel中,公式存在于单元格中,并在数据更改时更新-使用Python,会进行计算并存储值-如果手动更改了一部电影的总收入,则不会更新净收入。
让我们使用该sot_values方法按照创建的新列对数据进行排序,并按“净收入”显示前十部电影。

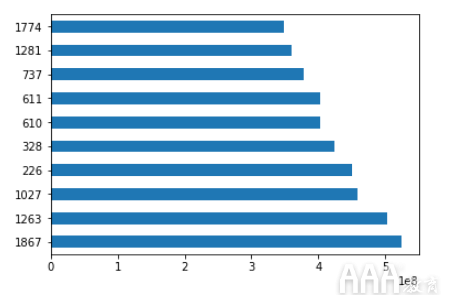
Pandas数据透视表
高级Excel用户还经常使用数据透视表。数据透视表通过将数据分组到索引上并应用诸如排序,求和或求平均之类的操作来汇总另一个表的数据。您也可以在Pandas中使用此功能。
我们需要首先确定将用作索引的一列或多列,以及将在其上应用汇总公式的列。让我们从小处开始,选择Year作为索引列,选择Gross Earnings作为汇总列,然后从该数据创建一个单独的DataFrame。
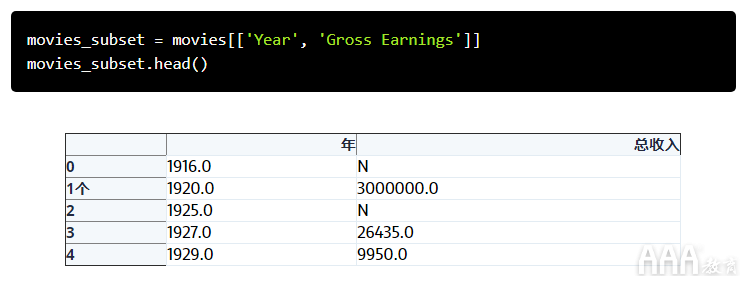
现在pivot_table,我们调用该数据子集。该方法pivot_table带有一个参数index。如前所述,我们要使用Year作为索引。
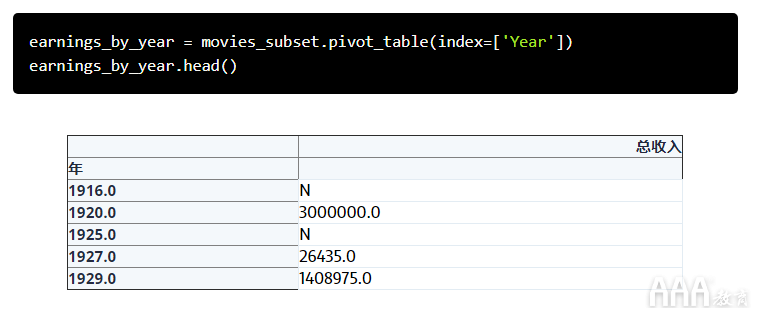
这为我们提供了一个枢纽分析表,其中按年份分组并汇总了总收入。注意,我们不需要明确指定“总收入”列,因为Pandas会自动将其标识为应应用汇总的值。
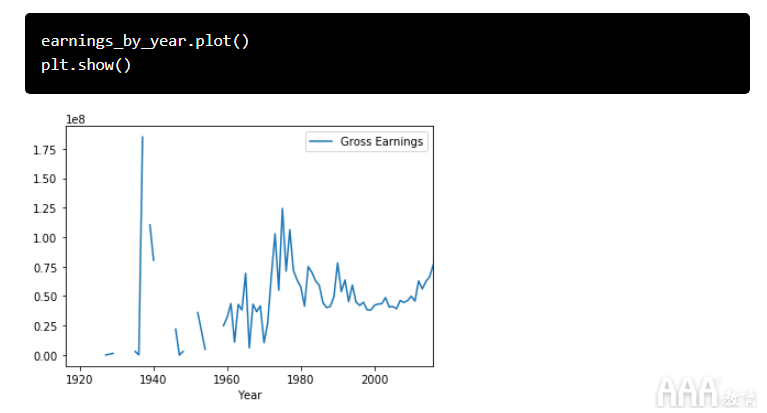
我们可以使用该数据透视表创建一些数据可视化。我们可以plot在DataFrame上调用该方法以创建线图,并调用该show方法以在笔记本中显示该图。
我们看到了如何以单个列作为索引进行数据透视。如果我们可以使用多列,事情将会变得更加有趣。让我们创建另一个DataFrame子集,但是这次我们将选择“国家/地区”,“语言”和“总收入”列。
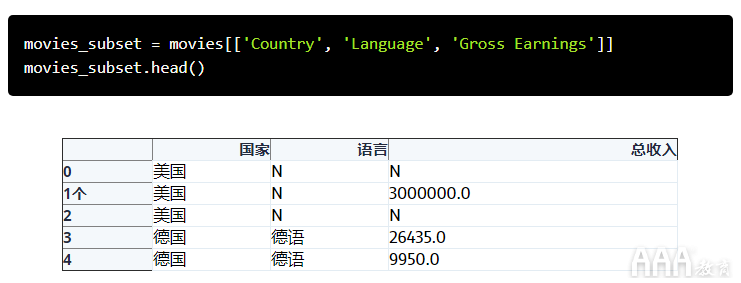
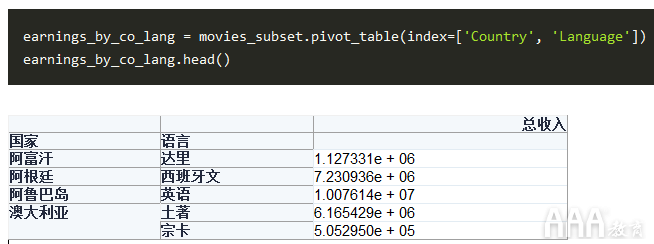
我们将使用“国家”和“语言”列作为数据透视表的索引。我们将使用毛收入作为汇总表,但是,我们不需要像前面看到的那样明确地指定它。
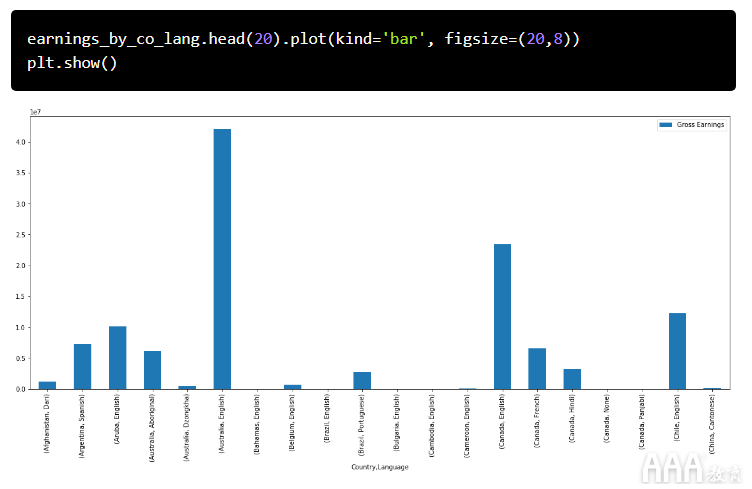
让我们用条形图可视化此数据透视表。由于此数据透视表中仍然有几百条记录,因此我们将只绘制其中的几条。
将结果导出到Excel
如果您要与使用Excel的同事一起工作,则将Excel文件保存在Pandas之外非常重要。您可以使用pandasto_excel方法将pandas DataFrame导出或写入Excel文件。Pandasxlwt内部使用Python模块来写入Excel文件。该to_excel方法在我们要导出的DataFrame上调用,我们还需要传递一个将写入此DataFrame的文件名。

默认情况下,索引也保存到输出文件中。但是,有时索引不提供任何有用的信息。例如,moviesDataFrame具有数字自动增量索引,该索引不是原始Excel数据的一部分。


您可以通过传递index-False来选择跳过索引。

我们需要能够使输出文件看起来更好,然后才能将其发送给我们的同事。我们可以将pandasExcelWriter类与XlsxWriterPython模块一起使用以应用格式。
我们可以通过创建一个ExcelWriter对象来使用这些高级输出选项,并使用该对象写入EXcel文件。

我们可以通过调用add_format要写入的工作簿来应用自定义项。在这里,我们将标题格式设置为粗体。

最后,我们通过save在writer对象上调用方法来保存输出文件。

例如,我们保存的数据的列标题设置为粗体。保存的文件如下图所示。
这样,可以XlsxWriter将各种格式应用于输出的Excel文件。
结论
Pandas不能替代Excel。两种工具在数据分析工作流程中都有自己的位置,并且可以成为非常出色的辅助工具。正如我们所展示的,Pandas可以执行许多复杂的数据分析和操作,这取决于您的需要和专业知识,可能超出仅使用Excel所能实现的范围。在Excel上使用Python和Pandas的主要好处之一是,它可以通过编写脚本并与自动化数据工作流程集成来帮助您自动化Excel文件处理。Pandas还具有从Excel文件读取各种数据的出色方法。如果您的目标受众更喜欢将结果从Pandas导出回Excel,则也可以。
另一方面,Excel是一个如此广泛使用的数据工具,忽略它不是一个明智的选择。掌握Pandas和Excel方面的专业知识并使其协同工作,可以为您提供技能,帮助您在组织中脱颖而出。
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 如何将Excel和Python和Pandas结合使用