



大数据分析如何使用R语言构建一个简单的成绩计算器
2020-09-24
点击量:次
1)进行计算
2)存储您的价值
3)使用特定功能回答问题
大数据分析如何使用R语言构建一个简单的成绩计算器基于我们新发布的R入门课程的一部分。该课程完全免费,并包含结业证书。去这里开始课程。
计算成绩
假设您是一名高中生,并且想要计算平均成绩(GPA)。GPA代表您在所有课程中累积的最终分数的平均值。您要参加七个课程,包括考试,家庭作业和项目,所有课程的权重均相等。我们假设GPA的测量范围是0-100。在数学课上,您92在考试,87家庭作业和85项目上都获得了满分。要计算平均数学成绩,我们可以编写以下内容:

我们可以手动执行诸如计算平均值之类的任务。但是,如果我们必须计算一千名学生的平均数,那么手工计算将不会有效利用我们的时间。相反,我们将使用编程来要求计算机执行计算。
执行计算
我们将从使用R作为基本计算器开始。我们先前编写了以下内容来计算数学课的最终成绩:

整个代码行称为表达式。我们将表达式写在称为脚本的文本文件中。脚本是我们提供给计算机的一组指令。用脚本编写表达式后,解释器将运行代码并在新窗口中显示表达式的结果。让print()我们以数学分数来运行语句,作为介于之间的表达式():

运行表达式,解释器将在新窗口中输出以下值:

注意:[1]当您深入研究向量时,“ ”将很有意义,但在大数据分析如何使用R语言构建一个简单的成绩计算器的上下文中您无需了解它。在我们显示的结果中,计算和print()语句都具有成对的匹配括号。为了更清楚一点,这里是相同的计算:

运行此表达式将产生与将所有内容写在一行上相同的结果。每个起始括号都需要一个闭合括号。让我们尝试删除右括号:

如果您的代码有错误,解释器将告诉您有错误以及该错误是什么。在我们的例子中,解释器返回:Error in parse(text = x, srcfile = src): :7:0: unexpected end of input。
文本unexpected end of input表示R解释器(我们的代码)的输入缺少右括号)。您可以尝试使用上面的表达式,看看还会遇到什么其他类型的错误。
执行多次计算
现在,我们已经使用该print()语句看到了结果,让我们更深入地研究R解释器如何运行代码。它:
1)扫描并查找语法错误。
2)从上到下解释并运行每一行代码。
3)运行最后一行代码时退出。
我们已经写了一个表达式来计算您在数学课上的最终成绩。要了解R代码的顺序解释方式,我们还要添加一个表达式来计算化学分数。在化学,你的得分分别为90,81和92。如果我们在单独的行上运行两个计算,会发生什么?

运行此代码,R解释器将显示:

如果我们编写两行代码,R是否总是显示两行?如果将代码分成多行怎么办?

R解释器仍将显示相同的值:
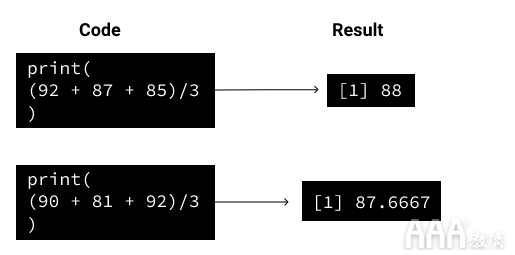
注意R如何解释我们的代码。每个print语句在结果中对应于它自己的一行:
如果我们想计算写作和美术的平均分数,可以在随后的每一行中写下这些表达式:
1)写作:84,95,79
2)艺术:95,86,93
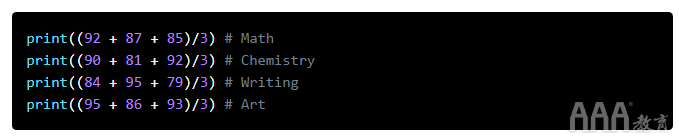
运行这些表达式将显示以下结果:

使用算术运算符执行计算
+并且/称为算术运算符。算术运算符用于执行数学运算。在下图中,您将找到最常用的运算

对于不熟悉幂运算的人,幂运算是一种使用**or ^运算符将数字本身乘以特定次数的方法。如果我们想将值4自身乘以3倍,则使用乘法*运算符将如下所示:

虽然使用乘法运算符将4乘以3并不太麻烦,但如果我们想将值4乘以20乘以,则使用乘法运算符并不是最有效的方法。相反,我们可以将计算表示为指数:

运行4**20将返回:

现在我们了解了算术运算符,让我们计算最后三个课程的最终成绩:历史,音乐和体育:
1)历史:77,85,90
2)音乐:92、90、91
3)体育:85、88、95

然后,解释器将显示:

按操作顺序执行计算
现在,我们已经了解了如何使用算术运算符来计算每个班级的平均分数,让我们回到数学的平均计算:

如果我们删除周围的括号92 + 87 + 85怎么办?

这将显示:

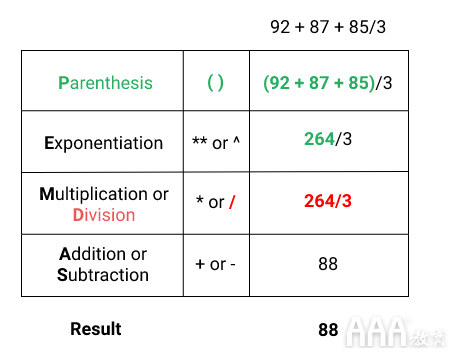
通过删除周围的括号92 + 87 + 85,R解释器进行不同的计算。使用多个运算符时,有一些规则可以确定执行计算的顺序。确定计算顺序的一种简单方法是在要首先执行的计算周围加上括号。这对于更复杂的计算非常有用,例如:

在这种情况下,我们在92 + 87 + 85 + 67 + 92 + 84和周围加了一个括号77 + 90 + 98。我们要告诉解释器在执行除法之前执行加法运算符。R解释器遵循数学运算规则的顺序。记住这一点的简单方法是PEMDAS:
1)P arentheses
2)Ë xponent
3)中号 ultiplication或d暂无报价
4)甲 ddition或小号 ubtraction
让我们看一个没有括号的例子。对于92 + 87 + 85/3,R解释器将按以下顺序计算表达式:

如果您没有在圆括号中包含括号92 + 87 + 85,则根据PEMDAS,R解释器将首先计算除法运算符。现在,让我们将括号重新添加到表达式中。对于(92 + 87 + 85)/3。R解释器将按差异序列计算表达式:
这是每个班级的最终成绩:
1)数学:88
2)化学:87.66667
3)写作:86
4)艺术:91.33333
5)历史:84
6)音乐:91
7)体育教育:89.33333
让我们计算总体平均值,同时牢记PEMDAS。在相同的表达式中计算出总体平均值后,从数学分数中减去该总体平均值:

创建评论
在前面的练习中,我们使用运算符进行了多次计算。稍后,当我们编写数百行代码时,组织代码是一种良好的编程习惯。我们可以通过插入注释来组织代码。注释是帮助人们(包括您自己)理解代码的注释。R解释器可以识别注释,将其视为纯文本,并且不会尝试执行它们。我们可以在代码中添加两种主要的注释类型:

1)内嵌评论
2)单行注释
内嵌注释内嵌注释在我们要注释或向特定语句添加更多细节时很有用。要在语句末尾添加内联注释,请从井号(#)开始,然后添加注释:

尽管我们不需要在井号(#)后面添加空格,但是这被认为是不错的样式,它使我们的注释更整洁,更易于阅读。单行注释单行注释跨越整个行,在我们要将代码分为几部分时很有用。要指定我们希望将文本行作为注释,请以井号(#)开始:
让我们在代码中添加注释!

给变量赋值
使用R进行简单的计算非常有用。但是,一种更可靠的方法是存储这些值以供以后使用。这种存储值的过程称为变量赋值。R中的变量就像可以保存值的命名存储单元。分配变量的过程需要两个步骤:
1)命名变量。
2)使用将值分配给名称<-。
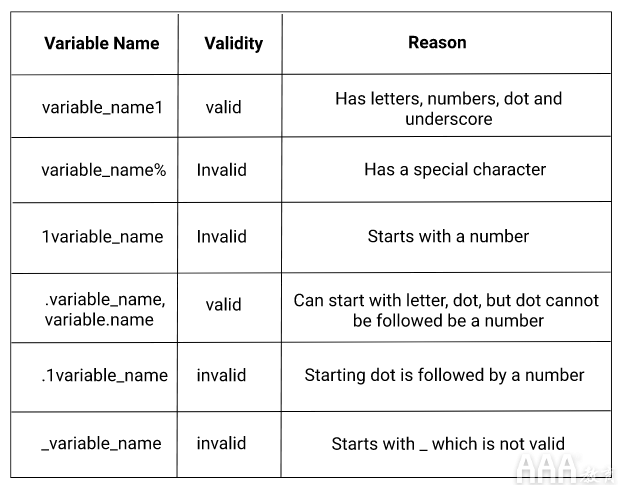
命名变量时,必须遵循一些规则:
1)变量名称由字母,数字,点或下划线组成。
2)我们可以以字母或点开头的变量。如果是点,那么我们不能在其后加上数字。
3)我们不能以数字开头的变量。
4)不允许使用特殊字符。
有关更多详细信息,请参见下表,详细列出了允许使用哪些变量名称和不允许使用哪些变量名称:
让我们返回数学分数计算:(92 + 87 + 85)/3,该计算的结果为88。要存储88在名为的变量中math,让我们编写以下表达式:

然后,如果我们尝试进行print()数学运算,像这样:

这将显示: [1] 88
变量不仅可以保存我们的计算结果,还可以分配表达式的值:

然后,如果我们尝试打印数学,像这样:

这将显示与我们原始计算相同的结果 [1] 88
我们已经将数学成绩存储在一个变量中。提醒一下,以下是课程和成绩:
1)化学:87.66667
2)写作:86
3)艺术:91.33333
4)历史:84
5)音乐:91
6)体育教育:89.33333
让我们将其他分数存储在变量中。

使用变量执行计算
现在我们已经将每个班级的成绩存储在变量中,我们可以使用这些变量来找到平均成绩。让我们看看我们的数学和化学分数:

在执行计算时,变量和值被视为相同。使用math和chemistry变量,88 + 87.66667与相同math + chemistry。使用变量执行计算时,PEMDAS规则仍然适用。如果我们想看看您在数学方面比化学方面的成绩要好得多,我们可以使用减法-算术运算符来找出差异:

显示:

如果我们想找到数学和化学的平均成绩,我们可以使用+,/,()对两个变量运营商:

显示:

完成这些计算后,我们还可以将这些表达式的结果存储在变量中。如果我们想将数学和化学的平均值存储在一个名为的变量中average,它将看起来像这样:

显示平均值将返回相同的值87.83334。
让我们使用以下变量来计算平均成绩:
1)math <- 88
2)chemistry <- 87.66667
3)writing <- 86
4)art <- 91.33333
5)history <- 84
6)music <- 91
7)physical_education <- 89.33333
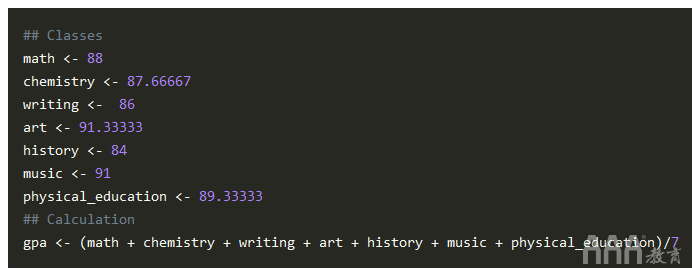
然后,让我们gpa从历史记录中减去您的历史记录,看看历史记录是否低于平均值。将此差异存储在中history_difference。

创建向量
在前面的示例中,使用变量计算平均成绩非常有用。但是,在数据科学中,我们经常处理数千个数据点。如果您获得每个班级每个家庭作业,考试或项目的分数,则我们的数据集将会很大。回到我们的数学,化学示例,让我们看一下当前的变量:

而不是店两个变量这两个值,我们需要一个可以存储在存储单元的多个值。在R中,我们可以使用向量存储这些值。向量是可以存储值序列的存储容器。然后,我们可以使用变量命名向量。像这样:
要创建矢量,您将使用c()。在R中,c()称为函数。与该print()语句类似,该c()函数接受多个输入并将这些值存储在一个位置。该c()函数不对值执行任何算术运算,而仅存储这些值。您可以在此处阅读有关该c()功能的更多信息。以下是创建矢量的步骤:
1)确定要存储在向量中的值,并将这些值放置在c()函数中。使用逗号分隔这些值,。
2)使用将向量分配给您选择的名称<-。
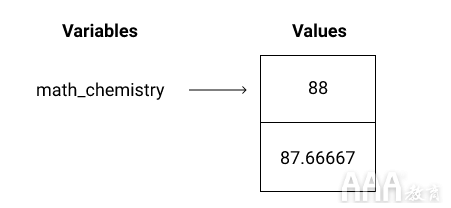
让我们创建一个包含数学和化学分数的向量。数学分数是88,化学分数是87.66667。

我们还可以使用您的变量名创建向量:

如果要这样做
print(math_chemistry),它将如下所示:
另一方面,如果我们尝试存储值序列,如下所示:

R解释器将仅尝试将88分配给,math_chemistry但在88之后将无法解释逗号:Error: unexpected ',' in "math_chemistry <- 88,"
让我们使用以下变量将最终分数存储在向量中:
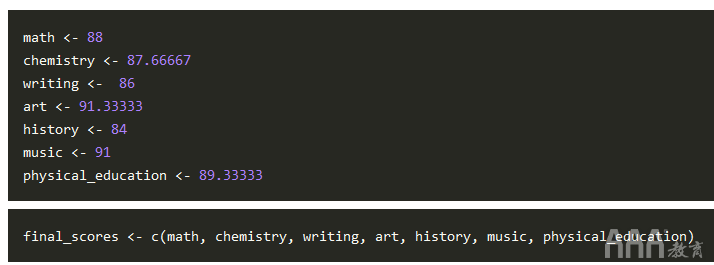
计算平均值
现在我们已经将您的成绩存储在矢量中,我们可以计算平均成绩了。在上一个练习中,您使用算术运算符来计算平均成绩:

尽管此解决方案有效,但该解决方案不可扩展。现在,您已经创建了一个向量,我们有了一种更简单的方法来计算平均成绩。要使用向量计算平均成绩,请使用mean()函数。该mean()函数将获取一个输入(向量)并计算该输入的平均值。然后,解释器将显示结果。让我们将mean()函数应用于math_chemistry向量:

这将返回:

让我们将该mean()函数应用于最终成绩矢量!

让我们将该mean()函数应用于最终成绩矢量!

对向量执行操作
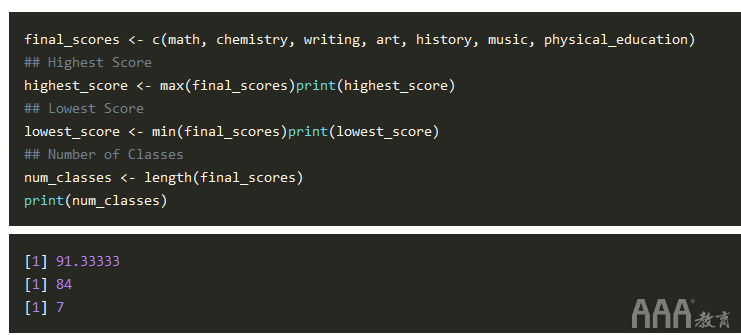
以前,您是使用mean()函数和向量计算最终成绩的。在数据科学中,您总是可以使用数据回答多个问题。让我们更深入地研究final_grades向量,然后再问几个问题:
1)最高分数是多少?
2)最低分数是多少?
3)你选了几节课?
要回答这些问题,您将需要一些其他功能:
1)min():找到向量中的最小值
2)max():在向量中找到最大值
3)length():查找向量拥有的值的总数
4)sum()::获取向量中所有值的总和(注意:本教程中将不使用。)
您可以应用此功能,类似于您应用
mean()功能。为了在math_chemistry向量中找到最大分数,我们将max()函数应用于该向量:

显示: [1] 88
让我们再回答几个有关您成绩的问题!
1)您在哪个班上得分最高?使用max()。
2)您在哪一门课程中得分最低?使用min()。
3)你选了几节课?使用length()。
下一步
如果您想了解更多信息,大数据分析如何使用R语言构建一个简单的成绩计算器基于我们的R基础知识课程,该课程是我们R轨道数据分析师的一部分。基于大数据分析如何使用R语言构建一个简单的成绩计算器中的概念,您将学习:
1)操作向量的更复杂方法:
a)索引到向量
b)过滤出向量中的不同值
c)向量的不同行为
2)使用矩阵提出大学建议
a)创建自己的矩阵
b)切片和重新组织矩阵
c)排序矩阵
3)使用数据框分析大学毕业生数据
a)数据框中包含的不同数据类型
b)选择并细分数据框中的特定值
c)将条件添加到数据框选择中
4)使用列表存储各种值
a)索引到列表
b)从列表中添加和减去值
c)合并清单
 长按识别二维码,加关注
长按识别二维码,加关注
- ↓ ↓ ↓ 继续阅读与本文标签相同的文章
- 大数据分析